
CHAPITRE XVII: La sécurisation des réseaux IP
Protéger son réseau et ses données
Dès lors qu’il permet à des centaines, voire à des milliers d’utilisateurs de communiquer et d’échanger des informations, le réseau pose inévitablement le problème de la sécurité : les informations qu’il véhicule possèdent de la valeur et ne doivent pas être accessibles à tout le monde.
La sécurité est un vaste sujet, qui dépasse le cadre du réseau tant sur les plans technique que méthodologique. Ainsi, ce chapitre ne traite pas des étapes essentielles que sont l’analyse de la valeur (qu’est-ce qu’on protège) et l’analyse de risque (contre quoi l’on se protège). Il ne traite pas, non plus, des protections appliquées aux postes de travail (anti-virus, par exemple) et aux applications (messagerie, serveurs Web, etc.).
Ce chapitre ne s’attache qu’à une petite partie de la sécurité, celle liée à la protection du réseau IP que nous venons de construire. Dans ce chapitre, vous apprendrez ainsi à connaître :
• les vulnérabilités des protocoles de la famille IP ;
• les différents types d’attaques ;
• les techniques de filtrage utilisées par les firewalls ;
• les architectures à contrôle de flux ;
• les principes des algorithmes de chiffrement ;
• les mécanismes de chiffrement, de contrôle d’intégrité, d’authentification et de signature ;
• les protocoles SSL et IPsec.
L’importance d’une politique de sécurité
Plus que partout ailleurs, définir une politique de sécurité dans le domaine des réseaux est avant tout un gage de cohérence et donc, d’une réelle protection. Sans cela, le développement anarchique des moyens de sécurité, ajoutés comme des surcouches au-dessus des réseaux, peut conduire à une complexité telle, qu’elle entrave la circulation de l’information.
Sur un petit réseau, couvrant un ou quelques sites, la complexité peut encore être maîtrisée, mais dans les grandes entreprises, le réseau permet l’échange de données de natures très diverses entre des populations aussi diverses que géographiquement dispersées. Dans tous les cas, la problématique reste la même ainsi que les moyens mis en œuvre pour la résoudre.
Trop souvent, les responsables sécurité imposent sans discernement des contraintes drastiques : un firewall par-ci, un autre point de coupure par-là, parce que tel type d’attaque est toujours possible. Et, ne sait-on jamais, tel autre cas de figure peut toujours se produire : il faut donc ajouter un autre mécanisme de protection.
Ces réflexes sécuritaires proviennent à la fois d’une responsabilisation excessive des personnes en charge de la sécurité et d’une méconnaissance technique des réseaux qu’ont ces mêmes personnes. Le réseau est alors perçu comme un organisme tentaculaire échappant à tout contrôle. Il est le vecteur de tous les maux réels ou imaginaires.
Ne connaissant pas ou pire, croyant savoir, ces responsables brandissent des menaces qui conduisent à une surenchère permanente, attisée en cela par les sociétés de conseil et les éditeurs qui vivent de ce commerce. Ne voulant prendre aucun risque, ils entretiennent la culture du secret et empilent des barricades.
Afin d’éviter ce cauchemar, il convient donc de ne pas faire de la sécurité pour la sécurité, mais de connaître la valeur de ce que l’on protège et contre quoi l’on se protège. À la suite de quoi, une réflexion technique permet de mettre en place les moyens de protection appropriés. En fin de compte, c’est le bon sens qui nous amène à ne pas utiliser le même type de clé pour la porte de son coffre-fort, pour la porte d’entrée de sa maison et pour celles des autres pièces.
La définition d’une politique de sécurité passe donc par :
- une analyse de la valeur des informations à protéger et une analyse des menaces ;
- l’application de règles et de procédures par les utilisateurs internes à l’entreprise ;
- la mise à jour permanente des logiciels de protection (firewalls, anti-virus...) et des correctifs pour les systèmes d’exploitation et les applications tels que les navigateurs Web ;
- la surveillance du réseau (enregistrement des événements, audits, outils de détection) ;
- la définition d’une architecture permettant de limiter les possibilités d’attaques et la portée d’éventuels dégâts causés par les pirates.
Les sections qui suivent traitent de ce dernier point en commençant par exposer les vulnérabilités, puis en présentant les différents types d’attaques.
Les vulnérabilités des protocoles IP
La famille des protocoles IP présente des failles de sécurité intrinsèques, car ils n’ont pas été conçus dans une optique de sécurité, mais plutôt dans une optique de résilience et de performance.
Il n’y a notamment :
- aucun chiffrement des données (les données et souvent les mots de passe circulent en clair) ;
- aucun contrôle d’intégrité (les données peuvent être modifiées par un tiers) ;
- aucune authentification de l’émetteur (n’importe qui peut émettre des données en se faisant passer pour un autre).
Les sections suivantes décrivent quelques-uns des protocoles les plus courants qui cumulent ces lacunes.
Telnet
L’identifiant et le mot de passe Telnet circulant en clair sur le réseau, il faut demander aux utilisateurs d’employer des mots de passe différents de ceux utilisés pour se connecter à des applications utilisant des protocoles mieux sécurisés. Interceptés, l’identifiant et le mot de passe pourront, en effet, être utilisés par un intrus pour se connecter à des applications dont les mots de passe sont, en ce qui les concerne, chiffrés.
De plus, les données sont véhiculées sous une forme non structurée, tâche qui est laissée à l’initiative de l’application. Il est donc très facile de transférer toutes sortes de données en profitant d’une session Telnet.

Ces deux caractéristiques font de Telnet un protocole très dangereux à utiliser entre une entreprise et Internet. Il doit donc être interdit. Sur le plan interne, son usage peut être autorisé, réglementé ou interdit, selon l’architecture de votre réseau, les mécanismes de sécurité mis en œuvre et la valeur des informations à protéger.
FTP
FTP
L’identifiant et le mot de passe circulant en clair, les recommandations énoncées pour Telnet s’appliquent également à FTP.

Le mode passif est beaucoup plus sûr que le mode normal, car il évite d’autoriser les connexions entrantes. Cependant, toutes les implémentations ne sont pas compatibles avec ce mode. Si tous vos clients et serveurs FTP supportent le mode PASV, il est recommandé d’interdire le mode normal.
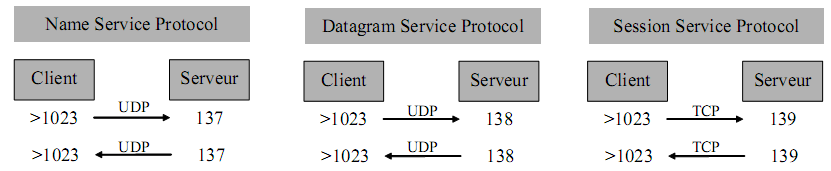
DNS
DNS
La recherche de noms et le transfert de zone (cf. chapitre 7) utilisent généralement les ports UDP (53↔53), mais si ces requêtes échouent, elles sont relancées via TCP (>1023↔53).
Certaines implémentations, ce qui est le cas avec les machines AIX, utilisent exclusivement TCP.

Aucun mot de passe n’est requis pour ces échanges, effectués automatiquement entre machines et ce, de manière transparente pour l’utilisateur. Par ailleurs, la commande nslookup (cf. chapitre 7) permet à tout utilisateur de consulter la base de données.
La base de données du DNS est particulièrement sensible, car elle contient l’ensemble des adresses IP de vos serveurs et équipements réseau, voire plus si vous utilisez Active Directory de Microsoft. Elle doit donc être protégée et en particulier être inaccessible depuis l’extérieur.
HTTP
Les serveurs Web peuvent répondre sur des ports spécifiques, autres que 80, tels les 8000, 8080, 8010 ou encore 81, pour ne citer que les plus courants. Ces ports non-standards ne présentent aucun intérêt en termes de sécurité, car les scanners permettent de les trouver rapidement.

En revanche, il est recommandé de séparer les données accessibles en FTP et en HTTP, soit sur deux serveurs différents, soit sur deux répertoires différents. Il est en effet facile de déposer un cheval de Troie sur un répertoire FTP, puis de le faire exécuter par le serveur HTTP. Sous Unix, il est en plus recommandé d’utiliser la fonction chroot.
Netbios
Le protocole Netbios (Network Basic Input Output System) est difficile à contrôler, car il transporte de nombreux protocoles propres à Microsoft : il s’agit de SMB (Server Message Block), de NCB (Network Control Bloc) et de toute une série de RPC (Remote Procedure Calls), qui sont utilisés par les environnements Windows.
Par exemple, les relations entre contrôleurs de domaines et entre clients et serveurs WINS emploient des relations complexes qu’il est difficile de filtrer. Pour ces raisons, l’utilisation de Netbios doit être interdite entre l’entreprise et Internet.
SNMP
Pour les requêtes « get » et « set » (cf. chapitre 6), le client est la plate-forme d’administration tandis que pour les messages « traps », le client est le matériel (réseau, serveur, etc.). Il est donc recommandé de cantonner ce protocole entre les stations d’administration et les équipements à surveiller :
- La plupart des implémentations utilisent UDP, et il faut l’autoriser dans les deux sens.
- Les noms de communauté circulent en clair.
- Les possibilités d’action offertes sont importantes (la commande « get » permet de faire un dump complet d’une configuration et la commande « set » permet de modifier la configuration).

On peut donc envisager de laisser passer les messages SNMP en filtrant les adresses source et destination.
La politique de filtrage peut cependant être plus souple au sein d’un même domaine de confiance ou dans le cas de réseaux entièrement commutés reposant sur des VLAN. Pour ce qui concerne Internet, le protocole SNMP doit être interdit.
RPC (Remote Procedure Calls)
De nombreuses applications, comme les logiciels de sauvegarde, utilisent les services du Portmapper qui répond sur les ports UDP et TCP 111 et qui renvoie au client un numéro de port aléatoire indiquant que le service est disponible sur sa machine.

Ce protocole ne peut pas être efficacement filtré, car de nombreux ports doivent être laissés ouverts de par la nature aléatoire de l’allocation. De plus, les firewalls génèrent de nombreux dysfonctionnements pour les applications qui utilisent les RPC. Les RPC doivent donc être interdits pour Internet.
NFS
Le protocole NFS utilise a priori le port UDP 2049, mais la RFC 1094 indique que ce n’est pas une obligation. Certaines implémentations utilisent en fait le Portmapper.
Un problème de sécurité important posé par NFS est celui lié au numéro de handle :
- Il est prédictible, car reposant sur la date création du système de fichier.
- Il est valable même lorsque le système de fichiers est démonté.
- Il est utilisable par quiconque l’ayant obtenu (par écoute réseau ou par calcul).
NFS est également vulnérable à la dissimulation d’adresse (spoofing), car le serveur se fie à l’adresse IP pour authentifier la machine cliente. Par ailleurs, les mécanismes setuid et nobody positionnés par l’administrateur du serveur demeurent des failles de sécurité, s’ils sont mal configurés.
ICMP
De nombreux services ICMP (cf. chapitre 6) peuvent renseigner un intrus, comme par exemple « destination unreachable », qui comporte des informations indiquant la cause du problème ou encore « echo request » et « echo reply », qui indiquent si un nœud est actif.
Les seuls paquets ICMP, qu’il est envisageable de laisser passer vers un autre domaine de confiance, sont les suivants :
- type 4 « source quench », qui permet de contrôler le flux entre un client et un serveur ;
- type 11 « time to live exceeded », qui évite le bouclage des paquets IP ;
- type 12 « parameter problem », qui indique une erreur dans un en-tête ;
- type 8 « echo request » et type 0 « echo reply », utilisés pour vérifier l’activité des nœuds pour des opérations de supervision et de diagnostic.
Vis-à-vis d’Internet, tous les services ICMP doivent être interdits : ils ne sont pas nécessaires et peuvent donner trop d’informations aux intrus.
Les différents types d’attaques
En plus de leur vulnérabilité, la famille des protocoles IP bénéficie d’une grande accessibilité : leurs spécifications sont rendues publiques avec les RFC, et Internet est un réseau ouvert à tous, aux particuliers comme aux professionnels. Les compétences techniques sont donc très répandues, et tout le monde est susceptible de trouver des failles et de lancer des attaques aussi bien sur le réseau public que sur notre réseau interne. Il est à noter que, selon la plupart des statistiques, environ 70 % des problèmes de sécurité ont des origines internes à l’entreprise.
Les attaques de type refus de service (denial of service)
Ce terme désigne un groupe d’attaques destiné à bloquer le service offert par un serveur (Web ou autre), un routeur ou un firewall. Le principe consiste à inonder de requêtes la machine cible de manière à ce qu’elle soit de plus en plus sollicitée, et ce, jusqu’à ce qu’elle ne puisse plus traiter les vraies requêtes des utilisateurs. Le pirate espère, de plus, qu’un débordement (saturation des capacités du logiciel) conduira à l’arrêt brutal de la machine, profitant ainsi d’une situation limite, non prévue par le programmeur (bogue).
Les parades consistent, la plupart du temps, à appliquer des correctifs (patches) qui permettent de traiter les cas de figure limites.
Les parades consistent, la plupart du temps, à appliquer des correctifs (patches) qui permettent de traiter les cas de figure limites.
Quelques exemples d’attaques par refus de service
L’attaque la plus classique, le ping de la mort (ping of death), consiste à bombarder la machine cible de paquets ICMP de type « echo_request ».
Une variante, appelée teardrop, consiste à envoyer des paquets ICMP de taille importante (plusieurs dizaines de Ko) de manière à activer les mécanismes de fragmentation IP. La plupart des machines s’arrêtent de fonctionner lorsqu’elles rencontrent ce cas de figure (fragmentation de paquets ICMP), à moins d’être équipées du correctif adéquat.
L’attaque land (littéralement atterrissage), consiste à générer un paquet ayant la même adresse IP source et destination que celle de la machine visée, et avec des ports (TCP ou UDP) source et destination identiques. La machine visée est de préférence un routeur, qui route le paquet indéfiniment pour lui-même. La parade consiste, là encore, à appliquer un correctif qui traite ce cas limite.
Les attaques par inondation SYN (syn flooding)
Dès qu’un client envoie une demande d’ouverture de connexion TCP à un serveur, l’échange normal est le suivant (cf. chapitre 5) :

Si le serveur ne reçoit pas le paquet ACK du client, il reste en attente de la réponse jusqu’à l’expiration d’un timeout.
L’attaque consiste donc, pour le pirate, à écrire d’abord un logiciel qui n’envoie jamais de paquets ACK en réception d’un paquet SYN du serveur, puis à inonder le serveur de demandes de connexions de ce type. Ceci entraîne le serveur à allouer de plus en plus de ressources pour les demandes de connexions TCP qui restent en attente, jusqu’à dépassement de ses capacités.
Le firewall protège contre ce type d’attaque en détectant puis en bloquant la requête après N paquets SYN consécutifs issus du même client ou à destination du même serveur.
La dissimulation d’adresses (spoofing)
Cette technique consiste, pour le pirate, à utiliser une adresse IP interne, c’est-à-dire celle d’un réseau de l’entreprise protégé par le firewall. Le but est de faire croire aux machines (serveurs, firewalls) qu’il s’agit d’un paquet issu du réseau interne, de manière à bénéficier des mêmes droits d’accès que nos utilisateurs comme, par exemple, l’équivalence de droits pour les remote commands Unix ou les règles de filtrages du firewall basées sur l’adresse source.
Les routeurs ne se soucient pas de savoir par quelle interface proviennent les adresses sources, car les algorithmes de routage doivent prendre en compte le cas de routes multiples et de secours.
En revanche, si le réseau interne est connecté à Internet, aucun paquet, ayant comme adresse source celle d’un réseau interne, ne doit en provenir. Le mécanisme d’antispoofing, utilisé par les firewalls, consiste donc à contrôler l’origine des paquets sur la base du couple « interface réseau physique » / « adresse IP source ».
Il est à noter que le même principe s’utilise avec les noms DNS et SMTP ou encore les mots de passe des procédures d’authentification.
Les attaques par tunnel
Le principe consiste à utiliser un port TCP ou UDP dédié à un service (Telnet, par exemple), pour faire passer des flux autres que ceux prévus.
Le cas le plus classique est celui du serveur SMTP qui permet de se connecter en Telnet, non pas sur le port 23 dédié habituellement aux serveurs Telnet mais sur le port 25 dédié aux serveurs SMTP. L’utilisateur peut ainsi dialoguer manuellement avec le serveur via les commandes SMTP.
Pour les cas de figure les plus évolués, les pirates développent des logiciels spécifiques capables de dialoguer avec un protocole donné sur n’importe quel port TCP ou UDP.
Le vol de session (session stealing, splicing ou hijacking)
Cette technique consiste à repérer une session TCP ouverte depuis l’intérieur sur un serveur situé sur Internet, puis à se substituer à ce serveur. La session ouverte par l’utilisateur interne devient ainsi un tunnel permettant d’opérer en toute quiétude.
Cette technique est très sophistiquée puisqu’elle nécessite de sonder le réseau Internet ou interne à des endroits bien précis, à trouver les numéros aléatoires qui identifient les paquets TCP au sein d’une session, puis à se substituer au serveur.
La seule parade réellement efficace consiste à chiffrer les données et à contrôler l’intégrité des paquets IP à l’aide du protocole IPsec.
Le rebond
Cette technique est la plus simple puisqu’elle consiste à profiter d’une faille de sécurité pour investir un serveur, puis, à partir de là, à se connecter à d’autres machines en utilisant les droits accordés à ce serveur.
La protection contre ce type d’attaque relève de la sécurisation des serveurs (mots de passe et correctifs) et de l’architecture (voir plus loin). En positionnant les serveurs les plus exposés sur un segment dédié, différent de celui hébergeant les machines les plus sensibles, un firewall peut contrôler les flux.
Les chevaux de Troie
Un cheval de Troie est un programme, importé sur une machine à l’insu de ses utilisateurs, qui se substitue à un programme normal, par exemple, au client FTP. Quand l’utilisateur lancera la commande FTP, au lieu d’utiliser son programme habituel, il lancera le faux FTP, dont l’interface utilisateur ressemble au vrai programme, à la différence qu’il ouvrira une session parallèle sur un serveur appartenant au pirate.
L’importation de tels programmes s’opère via la messagerie, une connexion directe à un serveur en profitant de ses failles de sécurité (mot de passe ou bogue), via la technique du tunnel ou, plus simplement, en installant le logiciel avec les droits d’accès de l’administrateur.
La première parade consiste à réaliser un contrôle d’intégrité sur les programmes binaires et les scripts, puis à vérifier qu’il n’y a pas eu de changement dans leur taille, leur date, etc. La seconde parade consiste à repérer en temps réel l’introduction d’un tel cheval de Troie en l’identifiant par sa signature (une série de codes binaires caractérisant les instructions qui le composent). Encore faut-il que ce cette signature soit connue et qu’elle ait été intégrée dans l’anti-virus chargé de cette détection, d’où l’importance des mises à jour fréquentes (hebdomadaires, voire journalières).
Les vers
Ce type de programme utilise le réseau pour se propager : installé sur une machine, non seulement il l’infecte, mais il cherche également d’autres machines sur le réseau pour essayer de s’y installer. Le ver désigne donc un mode de propagation qui peut intégrer les fonctions de virus, de scanner et de cheval de Troie.
À l’heure actuelle, tous ces programmes ne peuvent se propager qu’entre machines du même type, par exemple, entre PC Windows, entre Macintosh ou entre machines Unix. S’il s’agit d’un exécutable, les processeurs doivent, de plus, être de la même famille (pentium, power PC, etc.). S’il s’agit d’un script, le programme peut s’exécuter sur différents types de machines disposant du même système d’exploitation. Là encore, cette restriction est susceptible d’être levée dans le futur.
Le contrôle de flux
Les parades à ces vulnérabilités et à ces attaques sont de deux ordres : le contrôle de flux (qui accède à quoi et comment) et la confidentialité des données. Commençons par la première.
Le contrôle de flux consiste à filtrer les paquets IP selon les adresses source et destination, les ports TCP et UDP, les types de protocoles (ICMP, OSPF, TCP, UDP, etc.), et éventuellement, selon des informations issues des couches applicatives. Il peut être réalisé par les routeurs ou par des équipements dédiés appelés firewalls (pare-feu en français).
Les technologies utilisées par les firewalls
Quatre technologies sont utilisées pour contrôler les flux :
- le filtrage de paquet (packet filtering) ;
- le filtrage par état des sessions (stateful inspection) ;
- le relais applicatif (application gateway), encore appelé mandataire, ou, abusivement, application proxy, proxy gateway ou proxy tout court ;
- le relais de circuit (circuit relay ou circuit-level gateway).
La confusion quant à l’emploi du terme de « proxy » est historique : le NCSA (National Computer Security Association) a, le premier, utilisé le terme de « proxy service » fonctionnant sur un firewall appelé « application gateway ». Les journalistes ont ensuite cédé à la facilité en prenant pour raccourci le mot « proxy » pour désigner ce type de firewall. Par amalgame, les termes « application proxy » et « proxy gateway » ont ensuite été abusivement employés pour désigner le firewall alors qu’il désigne en réalité le processus. Le vrai
terme pour désigner ce type de firewall est donc « relais applicatif » (application gateway dans la littérature anglo-saxonne).
Un proxy, ou serveur proxy, désigne en réalité un serveur cache, c’est-à-dire une machine qui héberge les URL les plus récemment demandées dans le but d’économiser de la bande passante sur la connexion Internet (64 Kbit/s à 2 Mbit/s). Le navigateur Web est configuré de manière à interroger le serveur cache. Si l’URL demandée n’est pas dans le cache, le serveur relaie la requête vers le serveur cible. En toute rigueur, le proxy relaie la requête de la même manière qu’un firewall de type relais applicatif, mais on ne peut pas le considérer
comme un firewall à part entière, car il ne dispose pas des mécanismes de protection utilisés par cette classe de produit.
Pour ajouter à la confusion, le paramètre « proxy », qui est défini au niveau des navigateurs, indique à ces derniers de rediriger les requêtes Web à destination de l’extérieur vers un serveur spécialisé (à la manière du paramètre « default gateway » qui indique au protocole IP de rediriger les paquets à destination de l’extérieur vers un routeur). À l’origine, ce serveur était bien un serveur proxy (un cache), mais par la suite, l’utilisation de cette fonction a été étendue pour désigner les firewalls qui contrôlent les droits d’accès à Internet.
Il est à noter qu’à cette fonction de cache, vient s’ajouter celle déjà gérée au niveau de chaque navigateur Web.
Le filtrage de paquet
Le filtrage de paquet est historiquement parlant la première technique, encore largement utilisée par les routeurs. Elle consiste à filtrer chaque paquet individuellement au niveau de la couche réseau en fonction des adresses source et destination, du port TCP ou UDP, du type de protocole (ICMP, RIP, etc.), et du sens du flux. Très peu d’informations (alertes, statistiques) sont par ailleurs enregistrées et aucun mécanisme de protection n’est implémenté contre les attaques.
Le « stateful inspection »
La technologie stateful inspection reprend les principes du filtrage de paquet mais conserve un état (historique) de toutes les sessions. Les paquets ne sont plus filtrés individuellement, mais en fonction des précédents qui appartiennent à un même échange.
Pour ce faire, le firewall examine les données du paquet et remonte jusqu’à la couche transport, voire applicative. Le filtrage est bien réalisé au niveau 3 (couche réseau), mais en fonction d’informations issues des couches supérieures. De ce fait, il est également possible de filtrer au niveau applicatif (commandes FTP, SMTP, DNS, etc.).
Pour s’adapter aux protocoles qui utilisent des ports aléatoires (les ports client pour tous les protocoles et les RPC), les règles sont générées dynamiquement pour le temps de la session à partir des règles de base définies par l’administrateur.
En outre, seul le premier paquet d’une session est comparé aux règles de filtrage, les suivants étant seulement comparés à l’état de la session, d’où des gains de performance par rapport aux routeurs filtrants. C’est la technologie la plus rapide. Le relais applicatif
Cette technologie repose sur le principe du mandat : le firewall intercepte la requête du client et se substitue à ce dernier. En réalité, c’est donc le firewall qui envoie une requête au serveur. Il le fait de la part du client. Ce dernier croit dialoguer directement avec le serveur, alors que le serveur dialogue en fait avec un client qui est le firewall (le relais).
Cette technique implique de développer un client spécifique pour chaque application supportée (Telnet, FTP, HTTP, etc.), ce qui en fait la technologie la moins évolutive. Le support d’une application dépend des capacités de l’éditeur du produit.
La sécurité repose sur le fait qu’aucune connexion directe n’est réalisée entre le client et le serveur et que le client du firewall (le relais) est une version spéciale sans bogue, ne comportant aucune faille de sécurité, et susceptible d’intercepter les attaques.
Le relais de circuit
Le relais de circuit reprend la technologie de relayage sans permettre de filtrage au niveau applicatif et, surtout, sans tenir compte des spécificités liées à chaque protocole (échanges entre le client et le serveur, connexions ouvertes au sein d’une même session, etc.). Les paquets sont relayés individuellement. Cette technique offre donc un moins bon niveau de protection que le relayage applicatif.
Le premier produit à avoir introduit cette technologie est le freeware Socks. La mise en place d’un firewall Socks (on parle souvent de serveur Socks) requiert l’utilisation de clients (FTP, HTTP, etc.) spécifiques. Le client émet une requête au serveur Socks qui comprend l’adresse du serveur cible, le type de service demandé (port TCP ou port UDP) et le nom de l’utilisateur. Le serveur authentifie l’utilisateur, puis ouvre une connexion vers le serveur cible. Les flux de données sont ensuite relayés sans aucun contrôle particulier.
Cette technique est souvent utilisée en complément des relais applicatifs, plus particulièrement pour les protocoles non supportés par les relais, mais n’est jamais employée seule.
Comparaison des technologies
Les techniques de filtrage de paquet et de relais de circuit sont aujourd’hui obsolètes. Avec les techniques de piratage actuelles, il n’est pas envisageable de les utiliser sur un firewall.
Les technologies stateful inspection et relais applicatif dominent actuellement le marché des firewalls et sont, de plus en plus souvent, combinées. C’est, par exemple, le cas de Netwall, de Cyberguard, de Watchguard et, dans une moindre mesure, de Firewall-1.

La puissance de traitement des processeurs actuels permet de masquer les différences de performances entre les deux technologies pour des débits réseau compris entre 64 Kbit/s et 2 Mbit/s. La différence devient significative dans un réseau d’entreprise où le firewall doit supporter plusieurs interfaces Ethernet et de nombreuses règles de filtrage.
Choix d’un firewall
Il est recommandé d’utiliser deux firewalls de marque différente, un pour les connexions externes, dont Internet, et un autre pour le contrôle des flux internes :
- Si un pirate connaît bien un produit (et donc ses faiblesses), les chances qu’il en connaisse également un autre sont moindres.
- Un bogue présent sur un firewall a peu de chance de se retrouver également sur un autre.
Il est conseillé d’utiliser un firewall français pour les accès Internet :
Un firewall plus répandu peut, en revanche, être utilisé pour la sécurisation du réseau interne. Sa fonction est en effet plus liée au partitionnement du réseau.
- Leur origine offre plus de garanties qu’un produit étranger. Un firewall peut, en effet, comporter des trappes logicielles, sorte de portes dérobées (back-doors), qui contourne tous les mécanismes de protection du firewall, généralement au profit d’un service de renseignement. C’est tellement simple à réaliser et cela peut rapporter gros.
- Ils offrent les mêmes qualités que leurs homologues étrangers.
- Ils sont moins connus des pirates.
Un firewall plus répandu peut, en revanche, être utilisé pour la sécurisation du réseau interne. Sa fonction est en effet plus liée au partitionnement du réseau.

Comparaison entre les routeurs et les firewalls
On peut se poser la question de l’intérêt d’un firewall par rapport à un routeur. Rappelons cependant les avantages du premier sur le deuxième :
- meilleure protection aux attaques par refus de service et par dissimulation d’adresse ;
- analyse de l’état des connexions TCP et UDP pour chaque session (à la place d'un simple filtrage paquet par paquet ne tenant pas compte des sessions) ;
- plus grande richesse de filtrage ;
- visualisation en temps réel des sessions ouvertes ;
- journalisation des tentatives d’intrusion et remontée d’alerte ;
- ergonomie de l’interface d’administration.
Les routeurs sont bien dévolus à l’acheminement des paquets selon des contraintes autres que sécuritaires : calcul des routes, reroutage en cas de panne d’un lien, gestion de la qualité de service, diffusion multicast, ou gestion des interfaces et protocoles WAN.
Les firewalls sont, quant à eux, dévolus au filtrage des sessions et des applications selon des règles complexes. Alors que les routeurs agissent entre les couches 2 et 3 (liaisons et IP), les firewalls agissent à partir de la couche 3.
Sous la pression du marché, ces différences tendent cependant à s’estomper, et les routeurs embarquent désormais des firewalls. Cette intégration présente l’avantage de réduire les coûts et d’enlever un étage de complexité à la chaîne de liaison LAN - routeur - firewall - LAN - routeur - WAN.
Définition d’une architecture à contrôle de flux
Un firewall seul ne permet pas d’interconnecter des réseaux de manière sûre. Il ne suffit pas d’installer un firewall et de programmer quelques règles de filtrage. Cette approche vous procure plus un sentiment de sécurité qu’une réelle sécurité. Il convient plutôt de déterminer une architecture globale dont le firewall n’est qu’un des composants.
Les principes de base devant présider à la politique de filtrage sont les suivants :
- Les filtres sont positionnés sur les firewalls.
- Tout ce qui n’est pas expressément permis est interdit.
- Toute demande de connexion depuis Internet est interdite.
Les paquets TCP entrants doivent tous avoir le bit ACK positionné à « 1 » et le bit SYN à « 0 » (réponse à un paquet issu de l’extérieur).
En outre, plus le réseau de l’entreprise est grand, plus il peut être nécessaire de le partitionner et d’appliquer le concept de défense en profondeur. Ce principe consiste à définir plusieurs niveaux de protection de manière à ce que si le premier est pénétré (le firewall Internet, par exemple), les autres protègent des zones plus sensibles. Les dégâts causés par un pirate, un virus ou un ver, sont ainsi limités à la zone initiale d’attaque.
Ce principe, que nous retenons pour notre réseau, nous amène à définir la notion de domaine de confiance.
Une approche macroscopique permet de distinguer globalement deux domaines de confiance : le réseau interne couvrant les sites de notre entreprise et les réseaux externes regroupant les partenaires et sous-traitants. Une analyse plus détaillée montre que notre réseau se compose de trois grands ensembles :
Une approche macroscopique permet de distinguer globalement deux domaines de confiance : le réseau interne couvrant les sites de notre entreprise et les réseaux externes regroupant les partenaires et sous-traitants. Une analyse plus détaillée montre que notre réseau se compose de trois grands ensembles :
- les sites parisiens formant notre réseau interne ;
- le reste du Groupe et ses filiales formant le réseau de notre entreprise ;
- les utilisateurs en accès distant.
L’objet de l’étude est donc de décrire l’architecture à mettre en place sur notre réseau parisien. La sécurité est abordée du point de vue de notre réseau : ce sont les ressources situées sur notre réseau qu’il faut protéger.
Il est à noter que le choix du firewall est indépendant de l’architecture et relève d’une autre étude.
Acteurs et matrice de confiance
Un certain nombre d’acteurs et de ressources auxquels il nous faut accéder ont été identifiés et classés en fonction de critères propres à notre site parisien et faisant suite à une étude d’analyse de la valeur et d’analyse de risque. Ainsi, les niveaux de protection et de confiance indiqués ci-dessous sont ceux vus de notre site parisien, site sur lequel le firewall est mis en place. Le point de vue d’autres sites, mettant en place leur propre firewall, serait sans doute différent. Il s’agit ici de déterminer les protections à mettre en place sur le firewall de Paris.
Les valeurs des niveaux de confiance ont les significations suivantes :
0 Aucune confiance n’est faite à cet acteur (domaine de non-confiance).
1 Il est fait moyennement confiance à cet acteur, par exemple, parce qu’il fait partie de la même organisation, ou parce qu’il s’engage sur des niveaux de protection.
2 Pleine confiance est faite à cet acteur, car nous maîtrisons son réseau et ses ressources.
Les valeurs des niveaux de protection ont les significations suivantes :
0 L’architecture firewall n’a pas de ressources à protéger.
1 L’architecture firewall offre un premier niveau de protection, notamment par rapport à des acteurs externes à l’entreprise.
2 L’architecture firewall doit protéger absolument les ressources ; c’est ce pourquoi elle est mise en place.
La matrice de confiance est élaborée selon des critères qui dépendent amplement de considérations organisationnelles et techniques propres à chaque entreprise.

On peut donc dresser une cible de confiance, le centre étant le domaine à sécuriser, et les domaines devenant de moins en moins sûrs au fur et à mesure que l’on s’en éloigne. Les pointillés indiquent des limites non maîtrisées par notre entreprise et donc, un domaine de non-confiance.

Matrice de communication
Le tableau suivant précise quel acteur doit accéder aux ressources détenues par tel autre acteur.

En grisé, apparaissent les acteurs ayant un niveau de confiance inférieur à ceux détenant des ressources cibles. Il nous faut donc mettre en place des ressources partagées et augmenter la sécurité en isolant l’acteur ou la ressource sur un réseau dédié.
Le cas de l’acteur « Accès distants » est particulier, car il doit accéder directement aux ressources de notre entreprise, alors qu’il est situé dans un domaine de non-confiance. Ce qui signifie qu’il faut mettre en place des mécanismes de sécurité supplémentaires permettant de renforcer la sécurité.
On peut, dès lors, identifier trois segments dédiés hébergeant des ressources partagées :
- un segment « Accès distants » hébergeant des ressources dédiées aux accès distants ;
- un segment « Partenaires » partagé par les partenaires et notre site parisien ;
- un segment « Groupe » partagé par le Groupe et notre site parisien.
Les segments, communément appelés DMZ (DeMilitarized Zones), permettent ainsi d’éviter tout flux direct entre acteurs ayant des niveaux de confiance différents. De la même manière, les acteurs de niveaux de confiance différents seront placés sur des réseaux distincts, c’est-à-dire connectés à différentes interfaces du firewall.

Mécanismes de sécurité supplémentaires
Les protections contre les attaques et le contrôle de flux offerts par un firewall ne suffisant pas à se protéger des domaines de non-confiance, les mécanismes suivants permettent d’ajouter un niveau supplémentaire de sécurité vis-à-vis des réseaux externes tels ceux des partenaires :
- masquage des adresses internes par translation ;
- coupure des flux avec des relais applicatifs, de préférence intégrés au firewall ;
- interdiction des sessions Netbios et RPC, qui ne sont pas maîtrisables par les firewalls ;
- sécurisation des serveurs situés sur les segments dédiés par durcissement du système d’exploitation, restriction des droits d’accès et désactivation des services système et réseau non utilisés.
LES TRANSLATIONS D’ADRESSES ET DE PORTS (RFC 3022)
La translation d’adresse, appelée NAT (Network Address Translation) consiste à changer l’adresse source et/ou destination des paquets IP traversant un routeur ou un firewall. Ce type de mécanisme peut être utilisé à plusieurs desseins :
• masquage du plan d’adressage interne vis-à-vis de réseaux externes tels qu’Internet pour des questions de sécurité ;
• résolution des conflits d’adresses : lorsque deux sociétés fusionnent, la probabilité est non négligeable que leurs plans d’adressage soient identiques, surtout si elles respectent la RFC 1918 (cf. chapitre 5).
Pour Internet, la translation d’adresse a été la solution privilégiée pour palier à la pénurie d’adresses publiques, puisqu’à l’origine toutes les entreprises voulant se raccorder à Internet demandaient ce type d’adresses. Depuis, les entreprises optent majoritairement pour un plan d’adressage RFC 1918 ou privé hors RFC 1918 (c’est-à-dire des adresses non réservées auprès des organismes d’Internet), avec une translation d’adresse vis-à-vis de l’Internet et de leurs partenaires externes.
Il existe trois types de translations d’adresses :
• Dynamique N pour 1 : N adresses sources sont translatées en 1 adresse source. Vis-à-vis de l’extérieur, les paquets sont donc tous issus de la même source. Afin de distinguer les destinataires des paquets reçus en retour, le port TCP ou UDP source des paquets émis est également modifié et associé à l’adresse IP source originelle. Pour des protocoles comme ICMP, le discriminant est généralement un numéro de requête ou de session contenu dans le segment de données transporté dans IP.

• Dynamique N pour M (avec M ≤N), qui est une variante du précédent type. Si M est inférieur à N, le mécanisme de discriminant précédemment décrit est utilisé.
• Statique 1 pour 1 : chaque adresse est translatée en une autre adresse. Ce mode est surtout utilisé pour les adresses de destination correspondant à des serveurs à atteindre.
• Statique 1 pour 1 : chaque adresse est translatée en une autre adresse. Ce mode est surtout utilisé pour les adresses de destination correspondant à des serveurs à atteindre.

La translation de port PAT (Port Address Translation) consiste à modifier les ports destination dans le but d’ajouter un niveau de sécurité supplémentaire en conjonction avec un relais applicatif (cf. section traitant des firewalls).
Le firewall traitera des translations d’adresses pour masquer les adresses internes vis-à-vis des réseaux des partenaires. Cette traduction doit être statique pour les machines cibles auxquelles accèdent les partenaires et sous-traitants. Les clients sortants feront quant à eux l’objet d’une translation dynamique N pour 1.
Quant aux utilisateurs en accès distant, qui doivent néanmoins accéder aux ressources de notre réseau, il est difficile de les orienter vers des ressources partagées sur un segment dédié, car les mécanismes de réplication avec les serveurs internes seraient trop complexes, voire impossibles à mettre en œuvre. De ce fait, les mécanismes devant renforcer la sécurité doivent avoir trait à la confidentialité :
- authentification forte permettant de s’assurer de l’identité de l’utilisateur ;
- chiffrement des données afin d’assurer la confidentialité face aux réseaux externes traversés (réseau téléphonique, ADSL, etc.) ;
- contrôle d’intégrité permettant de s’assurer que les paquets IP (en-tête et données) ne sont pas modifiés.
Cas du DNS
Les partenaires disposent de leur propre DNS, qu’ils renseignent avec les adresses que nous leur donnons et auxquelles ils associent les noms souhaités. De cette manière, aucun échange n’est nécessaire entre leur DNS et le nôtre.
Quant à nos utilisateurs en accès distant qui peuvent être localisés n’importe où dans le monde, il est préférable de leur dédier un DNS qui contient des informations partielles.
Nous devons, en conséquence, considérer deux serveurs DNS :
- un vrai serveur DNS sur le réseau parisien à usage exclusif de nos utilisateurs ;
- un serveur DNS contenant des informations partielles à l’usage de nos utilisateurs en accès distant.
Chacun de ces serveurs réside sur son réseau ou segment respectif et appartient à un système DNS distinct, c’est-à-dire disposant de sa propre racine sans aucun échange avec l’autre.

Le DNS du réseau parisien fournit les informations aux clients du réseau parisien :
- Il gère le SOA siege.societe contenant les ressources situées sur notre réseau interne.
- Il gère le SOA partenaires.societe contenant les ressources des partenaires auxquelles nos utilisateurs doivent accéder. Ce SOA contient les adresses qui nous sont présentées par les partenaires et les noms connus par nos utilisateurs. Cette configuration présente l’avantage d’éviter tous flux DNS entre les réseaux Partenaires et notre réseau, ce qui renforce la sécurité. On suppose ici que le nombre de machines est raisonnablement limité de manière à ne pas compliquer les tâches d’exploitation.
- Il gère le SOA part-ext.siege.societe contenant les ressources situées sur le segment Partenaires. Ce SOA n’est connu que de nos utilisateurs.
- Les requêtes concernant d’autres SOA sont redirigées vers les serveurs compétents du Groupe via le serveur racine, utilisant en cela les mécanismes classiques du DNS.
Le DNS du segment Accès distants fournit les informations à nos utilisateurs en accès distant. Il gère une copie partielle du SOA siege.societe, qui contient uniquement les adresses et les noms des machines situées sur notre réseau interne et qui doivent être accessibles depuis l’extérieur. Ces adresses doivent être les mêmes que celles configurées dans les règles de filtrage du firewall.
Cas de Netbios
La résolution des noms Netbios utilise les serveurs WINS (Windows Internet Name Service) de Microsoft. Pour les mêmes raisons que DNS, le segment Accès distants doit disposer de son propre serveur, qu’il est préférable de paramétrer avec des adresses statiques. De cette manière, seules les machines explicitement autorisées seront visibles par les utilisateurs en accès distant, et le protocole WINS sera bloqué.
Un serveur WINS exporte ses ressources vers un autre serveur WINS en mode « push » via le protocole Nameserver sur le port TCP 42. Le montage de ressources disques et la messagerie Outlook utilisent, quant à elles, le protocole Netbios sur TCP 139, que nous devons laisser passer.
Les utilisateurs en accès distant doivent disposer de leur propre domaine de compte leur permettant d’accéder, par le biais des relations de confiance (au sens Windows du terme), au domaine de ressources du siège. Un PDC (Primary Domain Controler) doit donc être installé sur le segment Accès distants.
Il est toutefois possible de contourner les mécanismes de relations de confiance en utilisant la procédure « connect as ». Il faut donc filtrer les messages SMB correspondants. En revanche, les connexions entre les domaines Paris et Groupe utiliseront la procédure « connect as » afin d’éviter de diffuser tous les comptes (plusieurs milliers).
Il est toutefois possible de contourner les mécanismes de relations de confiance en utilisant la procédure « connect as ». Il faut donc filtrer les messages SMB correspondants. En revanche, les connexions entre les domaines Paris et Groupe utiliseront la procédure « connect as » afin d’éviter de diffuser tous les comptes (plusieurs milliers).
Services IP et matrice de flux
Chacune des ressources est accessible par un protocole et un numéro de port UDP ou TCP bien identifiés, qui vont servir de base au filtrage à appliquer sur le firewall. La matrice de flux ci-dessous présente les sens de connexion, ce qui n’interdit pas les échanges dans les deux sens. Ainsi, les connexions ne peuvent être initiées qu’à partir d’un réseau situé dans un domaine de confiance supérieur à un autre (exception faite de nos utilisateurs en accès distant), et aucune connexion ne peut être initiée depuis un segment.

Case vide = aucun service accessible. (1) Pour la population des exploitants uniquement.
Il est désormais possible de préciser l’architecture à mettre en place, de déterminer le plan d’adressage et les mécanismes de translation d’adresses.
Il est désormais possible de préciser l’architecture à mettre en place, de déterminer le plan d’adressage et les mécanismes de translation d’adresses.

Dans la mesure du possible, les serveurs utilisant des protocoles différents doivent être isolés sur des segments distincts, ce qui est le cas de Netbios, protocole difficilement maîtrisable. Cela permet d’appliquer une politique de filtrage plus restrictive, par adresse plutôt que par subnet. Si l’acteur Groupe avait eu un niveau de confiance égal à zéro, les serveurs accessibles via Netbios auraient même dû être installés sur des segments dédiés, de manière à éviter les rebonds entre serveurs Web et Windows. Même si les serveurs ne sont pas accessibles via ces deux protocoles, un cheval de Troie peut toujours l’utiliser.
Conformément à notre plan d’adressage défini au chapitre 5, les réseaux et segments dédiés autour du firewall partagent un réseau de classe C subneté sur 28 bits, 10.0.8.144/28, dans le but d’économiser des adresses. On obtient ainsi 16 sous-réseaux de 14 adresses chacun.
Cinq sous-réseaux, un par interface du firewall hors notre réseau interne, sont ici utilisés.
Le firewall ne fonctionne avec aucun protocole de routage dynamique tels qu’OSPF ou RIP, là encore pour des questions de sécurité. Le routage est donc statique entre les routeurs et le firewall.
La mise en place de relais ne se justifie pas sur un réseau interne, car d’une part nous exerçons un contrôle sur les acteurs avec qui nous sommes en relation (nos utilisateurs, les partenaires, le reste du Groupe), et d’autre part la diversité et la complexité des protocoles à filtrer ne permettent pas aux relais de fournir un niveau de sécurité supplémentaire. Le raisonnement vis-à-vis d’Internet serait, en revanche, différent, puisque nous aurions affaire à un réseau public, donc par définition non maîtrisé, et parce que le nombre de protocoles, nécessairement restreints, (HTTP, SMTP, etc.) seraient, de plus, facilement filtrables par des relais.
Le firewall ne fonctionne avec aucun protocole de routage dynamique tels qu’OSPF ou RIP, là encore pour des questions de sécurité. Le routage est donc statique entre les routeurs et le firewall.
La mise en place de relais ne se justifie pas sur un réseau interne, car d’une part nous exerçons un contrôle sur les acteurs avec qui nous sommes en relation (nos utilisateurs, les partenaires, le reste du Groupe), et d’autre part la diversité et la complexité des protocoles à filtrer ne permettent pas aux relais de fournir un niveau de sécurité supplémentaire. Le raisonnement vis-à-vis d’Internet serait, en revanche, différent, puisque nous aurions affaire à un réseau public, donc par définition non maîtrisé, et parce que le nombre de protocoles, nécessairement restreints, (HTTP, SMTP, etc.) seraient, de plus, facilement filtrables par des relais.
Matrice de filtrage
La matrice de flux permet d’élaborer la matrice de filtrage, c’est-à-dire les règles à implémenter sur le firewall. Celle-ci doit être construite sur le principe de l’ouverture de flux minimale : dans la mesure du possible, les flux doivent être ouverts entre couples d’adresses plutôt qu’entre couples de subnets. Ainsi :
- Les flux impliquant un serveur doivent être ouverts sur la base de l’adresse du serveur.
- Les flux impliquant des utilisateurs authentifiés doivent être ouverts sur la base des noms des utilisateurs (qui seront associés à une adresse lorsqu’ils seront authentifiés).
- Les flux impliquant des utilisateurs non authentifiés doivent être ouverts sur la base de leur subnet. Il est envisageable d’appliquer une politique de filtrage plus restrictive visà-vis des partenaires et de filtrer par couple d’adresses.
Une fois établie, la matrice doit pouvoir être directement transposée dans les règles de filtrage du firewall.
Rôle et fonctionnement des firewalls
L’objet de cette section est de montrer, avec l’exemple de Netwall, le fonctionnement d’un firewall et les fonctions qu’il remplit :
- protection active contre les attaques ;
- détection d’intrusion ;
- filtrage des paquets IP sur la base des adresses et des ports source et destination ;
- translation d’adresses IP (NAT) et des ports TCP/UDP (PAT) ;
- filtrage des commandes applicatives (HTTP, FTP, DNS, etc.) ;
- authentification des utilisateurs, permettant ainsi de filtrer les sessions par utilisateur et non plus sur la base des adresses IP sources ;
- chiffrement et intégrité des données à l’aide du protocole IPsec ;
- décontamination anti-virus, le plus souvent en liaison avec un serveur dédié à cette tâche ;
- filtrage des URL, soit directement, soit en liaison avec un serveur dédié ;
- filtrage des composants actifs (ActiveX, applet Java, Java scripts, etc.).
Il appartient à l’étude d’architecture de déterminer si toutes ces fonctions doivent être ou non remplies par un seul équipement et à quel endroit du réseau.
Architecture
Netwall fonctionne sur un serveur Estrella ou Escala avec le système d’exploitation AIX de Bull ou avec un AIX sécurisé, appelé BEST-X, qui est certifié F-B1/E3 par le CERT. Une version sous Windows reprend l’interface graphique, le module de filtrage IP et uniquement le relais SMTP. Netwall utilise simultanément deux technologies : le firewall est composé d’un module de filtrage IP, qui repose sur le principe de stateful inspection et de plusieurs relais applicatifs.

Le module de filtrage IP, qui réside au niveau du noyau Unix, est intercalé entre le driver de la carte et les couches IP. Tous les paquets entrants et sortants passent obligatoirement par le module de filtrage IP et, en fonction du protocole, sont ensuite transmis au relais applicatif correspondant.
La partie relayage applicatif de Netwall est constituée de plusieurs relais (démon Unix ou service NT), un par type d’application à relayer (Telnet, SMTP, etc.) dérivés des sources du kit TIS (Trusted Information Systems) et de Netscape Proxy Server pour le relais HTTP.
Les relais sont lancés dans un environnement restreint (chroot) et sans les privilèges superviseur (root). Ils ne reçoivent jamais les flux directement.
Fonctionnement
Tous les flux pour un service particulier (Telnet, SMTP, etc..) sont obligatoirement traités par le relais applicatif correspondant. Si un relais s’arrête de fonctionner (arrêt manuel, disque plein ou bogue), le module de filtrage IP bloque le service associé.
Le module de filtrage IP offre toutes les caractéristiques présentées par la technologie stateful inspection :
- Il garde une trace de toutes les sessions (TCP, UDP, RPC, etc.).
- Il génère dynamiquement les règles de filtrage.
- Il analyse au niveau applicatif (FTP, RPC, etc.).
- Il gère la fragmentation IP.
Les règles sont définies dans une base appelée ACL (Acces Control List). Pour chacune d’entre elles, on définit l’action à entreprendre (accepter, rejeter, authentifier), le niveau d’information à enregistrer pour les événements (normal, détaillé, debug) et la manière de remonter une alerte (trap SNMP, e-mail, pager ou déclenchement d’un script personnalisé).
Les règles peuvent être activées pendant des périodes données (heure, jour de la semaine).
Les protections contre le spoofing, les attaques par inondation syn, les ping of death, etc., sont activées au niveau du module de filtrage IP, entre le driver réseau et la couche IP.
La configuration des interfaces est particulière. Trois types d’interfaces sont prédéfinis à la base : interne, externe et DMZ (DeMilitarized Zone). Lorsque le firewall est configuré avec plus de trois interfaces, l’administrateur doit définir des domaines de sécurité basés sur les réseaux IP puis affecter les interfaces à un domaine. La définition des règles est ensuite réalisée à partir de ces domaines.
Relais applicatif
Les applications relayées sont HTTP, FTP, SMTP et Telnet. Chaque relais gère le contrôle de flux, le filtrage des commandes (HTTP, FTP, SMTP), l’authentification, l’enregistrement des événements et la connexion vers la machine cible.
Deux processus SMTP séparés fonctionnent, un pour les connexions avec Internet et l’autre pour les connexions internes. Le relais SMTP empêche toute connexion directe à partir d’un client Telnet sur port 25.
Les autres protocoles peuvent être traités par un relais générique fonctionnant sur le mode relais de circuit : la demande de connexion est interceptée pour authentifier la session, puis la connexion est autorisée vers le serveur cible. Les flux sont ensuite relayés sans contrôle particulier, autre que celui réalisé par le module de filtrage IP.
Le relais HTTP offre les fonctions suivantes :
- gestion des changements de mots de passe utilisateur depuis un navigateur ;
- filtrage des URL ;
- filtrage des applets Java et des scripts Java.
Les composants ActiveX peuvent également être filtrés.
Cas des protocoles non relayés
Tous les protocoles, qu’ils soient relayés ou non, sont traités par le module de filtrage IP sur le mode stateful inspection. Les protocoles non relayés sont donc traités au niveau du noyau.
Les paquets peuvent être filtrés en fonction du protocole (UDP, TCP, ICMP), des adresses source et destination, du port (UDP ou TCP) ou sur le champ « option » situé dans l’en-tête du paquet IP.
Authentification
L’authentification est gérée individuellement par chaque relais applicatif et globalement par le module de filtrage IP. Les niveaux de fonctionnalités sont cependant différents.
Tous les protocoles peuvent être authentifiés par le module de filtrage IP via la carte à puce CP8 de Bull. Cette solution nécessite un lecteur de carte sur le poste de l’utilisateur et un serveur CP8LAN. L’authentification est transparente pour l’utilisateur : le firewall intercepte une demande de connexion et demande l’autorisation au serveur CP8LAN qui interroge la carte de l’utilisateur. Dans le cas d’une réponse positive, le firewall permet aux paquets de passer. Si la carte CP8 est retirée de son lecteur, le serveur CP8LAN la détecte et en informe le firewall qui ferme toutes les sessions de l’utilisateur en question. Les communications entre les clients, le firewall et le serveur CP8LAN sont chiffrées via DES.
Les proxy FTP et Telnet supportent, en plus, les authentifications via S/Key, SecurID, les mots de passe Unix classiques et également ISM/Access Master. En revanche, le relais HTTP supporte uniquement le mode classique (mot de passe non chiffré) et la variante chiffrée via SSL.
Deux procédures de connexion sont proposées aux utilisateurs :
- mode non transparent : l’utilisateur se connecte d’abord sur le firewall pour s’authentifier, puis ouvre une session sur la machine cible et, éventuellement, s’authentifie à nouveau ;
- mode transparent : l’utilisateur se connecte directement sur la machine cible, mais cette demande est interceptée par le firewall, qui demande une authentification préalable. La session est alors relayée normalement par le relais.
Translation d’adresses
Deux modes de translation sont proposés :
- Le mode statique offre une gestion au niveau du module de filtrage IP : chaque adresse est translatée en une adresse (mode 1→1) qui sera seule visible de l’extérieur (par rapport à l’interface d’où elle provient).
- Le mode dynamique offre une gestion au niveau des relais applicatifs : les adresses d’un réseau ou d’un sous-réseau sont translatées en une seule (mode n→1 dit de masquage).
Netwall prend en compte les protocoles DNS et Netbios, qui présentent la particularité de transporter les adresses IP dans la partie « données » des paquets.
Redondance
Un module complémentaire, appelé SafeNetwall, permet d’offrir le partage de charge et la redondance entre deux firewalls. Les deux machines dialoguent via une interface Ethernet de préférence dédiée pour des questions de sécurité. Les sessions en cours ne sont pas coupées.
Administration
L’administration du firewall peut être réalisée de différentes manières :
- à partir d’une interface graphique X/Windows ;
- à partir d’un navigateur Web via HTTP ;
- via des menus en mode texte (interface SMIT fournie en standard avec AIX).
Si la station est déportée, les sessions avec Netwall sont authentifiées via DES et l’intégrité des données est contrôlée par une signature DES. Les paquets en eux-mêmes ne sont pas chiffrés. Les accès au firewall peuvent être contrôlés via les mécanismes propres à ISM/Access Master.
Les statistiques affichées en temps réel comprennent le nombre de paquets traités et rejetés ainsi que les ressources système utilisées. L’administrateur peut, à travers l’interface graphique, modifier des paramètres système tels que la taille des caches, les files d’attente et les tampons utilisés pour la fragmentation.
Un produit distinct, appelé Netwall Partitioner, permet de générer des règles de filtrage pour différentes plates-formes : les routeurs Cisco et NCS ainsi que les firewalls Netwall et PIX (Cisco).
Log et audit
Comme pour les autres fonctionnalités, les événements sont générés à deux niveaux : relais applicatifs et module de filtrage IP. Ils sont enregistrés dans deux types de fichiers : audit et alertes.
Le module de filtrage IP enregistre dans le fichier d’audit les adresses IP source et destination, les ports, l’en-tête du paquet (mode détaillé), le contenu du paquet (mode trace) et la date de l’interception. Le fichier des alertes contient les adresses IP source et destination, les ports, les protocoles et la date de l’événement.
Les relais enregistrent des informations propres à leur application (FTP, Telnet, HTPP, etc.) : heure de début et durée de la session, nombre d’octets échangés, adresses source et destination, nom de l’utilisateur et informations sur les sessions d’authentification. En mode trace, le contenu du paquet est également enregistré.
Les alertes peuvent être déclenchées à partir d’un événement simple (rejet d’un paquet, refus d’authentification) ou sur des conditions spécifiques fondées sur le nombre d’occurrences d’un événement ou sa fréquence (nombre d’occurrences de l’événement pendant une période donnée).
Mécanismes de protection
La fragmentation des paquets est gérée de la manière suivante : lorsqu’un fragment arrive et qu’il n’est pas le premier d’une série, il est mémorisé jusqu’à la réception du premier fragment qui contient toutes les informations. Cette approche est à double tranchant : elle offre plus de sécurité puisque tous les fragments sont lus avant le traitement complet du paquet, mais elle est potentiellement vulnérable aux attaques de type teardrop, puisqu’il faut allouer de la mémoire pour stocker les fragments.
Intégrité
Le module de filtrage IP bloque par défaut tout le trafic et contrôle l’activité des autres processus. Si l’un d’eux s’arrête, le module de filtrage IP bloque le trafic correspondant. Les fonctionnalités liées à la TCB (Trusted Computing Base) peuvent être étendues à Netwall et vérifier l’intégrité des fichiers (checksum sur le contenu, date de modification, propriétaire).
Chiffrement des données
Le firewall est compatible avec les VPN (Virtual Private Network) IPsec. Pour des débits supérieurs à quelques Mbit/s, mieux vaut utiliser un boîtier dédié appelé SecureWare.
Remarques sur l’administration des firewalls
Il faut souligner que, dans tous les cas de figure, la sécurité réclame une administration continue. Une équipe d’exploitation doit être formée spécifiquement aux techniques liées à la sécurisation des réseaux IP et au firewall lui-même. Les tâches sont notamment les suivantes :
- positionnement des règles de filtrage ;
- analyse de toutes les règles de filtrage (une règle peut en effet mettre en défaut toutes les autres) ;
- gestion des autorisations d’accès ;
- analyse et purge des log.
La confidentialité
La sécurité, exprimée en termes de confidentialité, recouvre plusieurs fonctionnalités :
- le chiffrement des données ;
- l’intégrité des données, qui consiste à vérifier que les données reçues sont bien celles qui ont été originellement émises ;
- la signature, qui consiste à s’assurer qu’un objet a bien été émis par celui qui prétend l’avoir fait ;
- le certificat, qui consiste à s’assurer que la clé publique du destinataire est bien la sienne.
Les mécanismes mis en œuvre pour ces fonctionnalités reposent sur les algorithmes de chiffrement. Des protocoles intègrent ensuite ces algorithmes dans des applications telles que les échanges réseau au sens large, les cartes bancaires, le paiement électronique, etc.
Les algorithmes de chiffrement
Il existe trois catégories d’algorithmes de chiffrement :
- les algorithmes à clé secrète, dits symétriques : l’émetteur doit partager une clé secrète avec chacun des destinataires ;
- les algorithmes à clé publique, dits asymétriques : deux clés (une privée et une publique) peuvent chiffrer et déchiffrer un message ;
- Les algorithmes à clé secrète non réversibles.
Les algorithmes symétriques nécessitent qu’émetteur et destinataire se soient, préalablement à tout échange, mis d’accord sur un mot de passe connu d’eux seuls. Chaque émetteur doit donc gérer autant de clés qu’il a de correspondants. Les algorithmes de ce type les plus répandus sont DES (Data Encryption Standard), une version améliorée appelée Triple DES, RC4, RC5, RC6, IDEA (International Data Encryption Algorithm) et AES (Advanced Encryption System), le successeur désigné de DES.
Le principe des algorithmes asymétriques est le suivant :
- La clé publique de B est diffusée auprès de tous ses correspondants.
- Une personne A, désirant envoyer un message à B, chiffre le message avec la clé publique de B.
- B est le seul à pouvoir déchiffrer le message avec sa clé privée.
Il est à noter que les clés sont commutatives :
- Il est possible de chiffrer avec la clé publique et de déchiffrer avec la clé privée.
- Il est possible de chiffrer avec la clé privée et de déchiffrer avec la clé publique.
Cette propriété est utilisée pour la signature numérique (voir plus loin).
L’avantage d’un algorithme asymétrique est qu’un destinataire B n’a besoin que d’une clé pour tous ses correspondants. Avec un algorithme symétrique, il faut en effet une clé secrète à partager avec chaque correspondant (à moins qu’on accepte l’idée que chaque correspondant puisse déchiffrer les communications entre B et quiconque partageant la même clé).
Les algorithmes à clé publique les plus en pointe actuellement sont RSA (Rivest, Shamir et Adleman), et ECC (Elliptic Curve Cryptosystem).
Les algorithmes non réversibles consistent à transformer un message en un mot de 128 bits ou plus. L’algorithme de hachage utilisé doit être à collision presque nulle, c’est-à-dire que la probabilité que deux messages différents produisent le même mot de 128 bits, doit être la plus faible possible. Les algorithmes de ce type les plus répandus sont MD5 (Message Digest – RFC 1319 et 1321) et SHA (Secure Hash Algorithm).

FIPS = Federal Information Processing Standard : normes édictées par le NIST.
Efficacité des algorithmes de chiffrement
La performance d’un algorithme à clé (secrète ou publique) se caractérise par son inviolabilité qui repose sur deux facteurs :
- un problème mathématique, réputé insoluble (un « hard problem »), souvent basé sur la factorisation des grands nombres premiers en utilisant des modulos dans des groupes générateurs Zp ;
- la longueur de la clé : 40, 56, 128 et 1024 étant des valeurs courantes.
Le tableau suivant présente le temps mis pour trouver une clé DES. Il est extrait d’un rapport rédigé en 1996 par sept spécialistes parmi lesquels Rivest (de RSA), Diffie (de DiffieHellman) et Wiener (auteur d’une méthode permettant de casser l’algorithme DES).
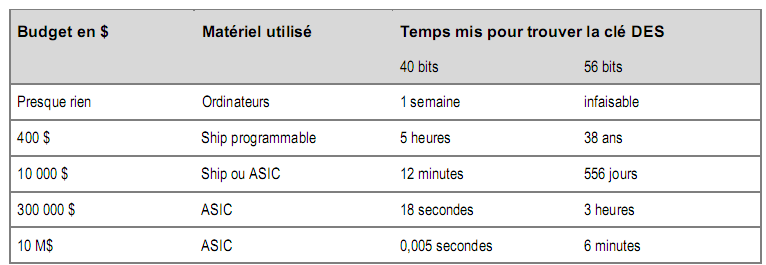
Depuis, les choses ont bien évolué : un étudiant de l’École polytechnique a réussi à casser la clé 40 bits de l’algorithme RC4 en 3 jours, rien qu’en utilisant les temps CPU libres de super-calculateurs. Le record est détenu par des étudiants de l’université de Berkeley qui, en février 1997, ont cassé la clé en 3 heures 30 à l’aide de 250 stations de travail en réseau.
La société RSA, qui commercialise l’algorithme du même nom, a organisé un concours dont le but était de casser la clé 56 bits de l’algorithme DES, épreuve remportée par un consultant indépendant.
L’infaisabilité de la propriété mathématique utilisée par l’algorithme est également un critère important : par exemple, ECC à 128 bits est aussi sûr que RSA à 1024 bits, et RSA à 40 bits est aussi sûr que DES à 56 bits.
Tout organisme privé ou public peut investir dans la production d’un ASIC spécialisé. La hauteur de son investissement dépend simplement du gain qu’il peut en tirer, d’où l’intérêt de bien évaluer la valeur commerciale de l’information à protéger.
En conclusion, les clés à 40 bits sont aujourd’hui considérées comme non sûres et l’algorithme DES comme obsolète.
La société RSA, qui commercialise l’algorithme du même nom, a organisé un concours dont le but était de casser la clé 56 bits de l’algorithme DES, épreuve remportée par un consultant indépendant.
L’infaisabilité de la propriété mathématique utilisée par l’algorithme est également un critère important : par exemple, ECC à 128 bits est aussi sûr que RSA à 1024 bits, et RSA à 40 bits est aussi sûr que DES à 56 bits.
Tout organisme privé ou public peut investir dans la production d’un ASIC spécialisé. La hauteur de son investissement dépend simplement du gain qu’il peut en tirer, d’où l’intérêt de bien évaluer la valeur commerciale de l’information à protéger.
En conclusion, les clés à 40 bits sont aujourd’hui considérées comme non sûres et l’algorithme DES comme obsolète.
LE POINT SUR SSL / TLS (RFC 2246 ET 3546)
Le protocole TLS 1.0 (Transport Layer Security) est la version standardisée du plus connu SSL 3.0 (Secure Socket Layer). Il permet d’authentifier le serveur et, éventuellement, le client, ainsi que de chiffrer et de contrôler l’intégrité des données de bout en bout entre un PC et un serveur. Le principe repose sur l’utilisation de clés publiques diffusées sous forme de certificats X.509, c’est-à-dire signées par une autorité de certification. Dans le cas du paiement électronique, c’est le serveur, sur lequel est effectué le paiement, qui envoie son certificat, mais certaines applications peuvent requérir un certificat de la part du client afin d’authentifier ce dernier.
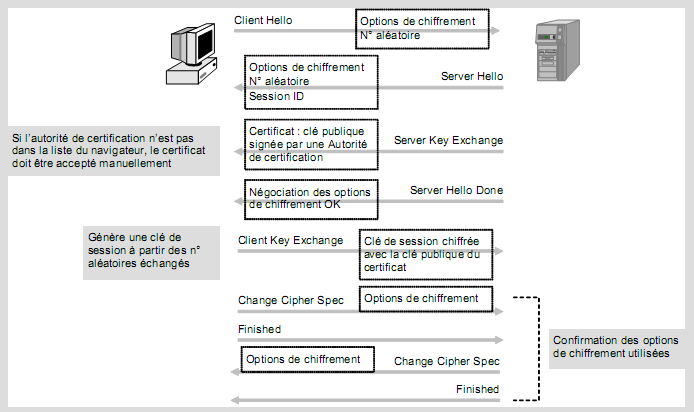
La clé publique (1024 bits ou plus) sert à chiffrer la clé de session à l’aide d’un algorithme asymétrique tel que RSA. La clé de session (128 bits au minimum, 40 bits étant courant mais pas suffisant) est utilisée pour chiffrer les données avec un algorithme symétrique tel que 3DES ou IDEA (RC4 et DES étant courants mais trop faibles). Un algorithme non réversible, tel que MD5 ou, mieux, SHA, est utilisé pour contrôler l’intégrité des données échangées.
De nombreux protocoles reposant sur TCP (pas UDP) existent en une version SSL :
Le chiffrement est très consommateur de ressources CPU, d’autant qu’une page Web comportant 4 images nécessite la création de 5 sessions SSL (une pour chaque requête GET), ce qui signifie 5 négociations séparées. Des boîtiers dédiés sont donc souvent positionnés devant les serveurs devant traiter plusieurs sessions SSL en parallèle. Enfin, bien que la plupart des navigateurs supportent SSL 2.0 et 3.0, il est fortement recommandé de ne pas utiliser la version 2.0, qui comporte des failles de sécurité connues.
Les protocoles de sécurité
L’intégration des algorithmes à des produits commerciaux est rendue possible grâce aux protocoles de sécurité. Ceux-ci comprennent, au minimum, le chiffrement, mais peuvent également prendre en compte l’intégrité des données, la signature, ou encore la gestion des certificats.
L’intégration des algorithmes à des produits commerciaux est rendue possible grâce aux protocoles de sécurité. Ceux-ci comprennent, au minimum, le chiffrement, mais peuvent également prendre en compte l’intégrité des données, la signature, ou encore la gestion des certificats.

Ces protocoles définissent les échanges, le format des données, les interfaces de programmation et l’intégration dans un produit. Par exemple, SSL (Secure Socket Layer) et SHTTP sont destinés aux navigateurs Web alors que S/Mime et PGP/mime s’intègrent à la messagerie Internet.
L’intégration de ces algorithmes est décrite par le standard PKCS sous la forme de profils décrits dans le tableau suivant.

L’intégration de ces algorithmes est décrite par le standard PKCS sous la forme de profils décrits dans le tableau suivant.

Ainsi, S/MIME repose sur les standards PKCS #1, #3, #7 et #10. De même, le GIE Mastercard/Visa utilise PKCS #7 comme base des spécifications SET (Secure Electronic Transaction). Les algorithmes retenus sont RSA 1024 bits pour la signature et l’enveloppe, DES 56 bits pour le chiffrement (uniquement pour des faibles montants) et Triple DES.
Les protocoles d’échange de clés
Le problème des algorithmes symétriques réside en la diffusion préalable de la clé entre les deux parties désirant échanger des messages : le destinataire doit connaître la clé utilisée par l’émetteur, la clé devant demeurer secrète. Le moyen le plus simple est l’échange direct ou via un support autre qu’informatique. Outre les problèmes de confidentialité, des problèmes pratiques peuvent survenir, surtout s’il faut changer souvent de clé.
Afin d’éviter cela, d’autres algorithmes ont été développés. Il s’agit de :
- Diffie-Hellman ;
- SKIP de SUN ;
- PSKMP (Photuris Secret Key Management Protocol) ;
- ECSVAP1 et ECSVAP2 (Elliptic Curve Shared Value Agreement Protocol) ;
ISAKMP (Internet Security Association and Key Management Protocol), Oakley et Skeme ;
IKE (Internet Key Exchange) utilisé par IPsec.
L’algorithme de Diffie-Hellman est le plus connu. Son principe est le suivant :
- Soit un générateur g du groupe Zp où p est un grand nombre premier.
- A choisit une clé a, calcule ga et l’envoie à B.
- A choisit une clé b, calcule gb et l’envoie à A.
- A calcule (gb)a et B calcule (ga)b.
- On obtient la clé secrète (gb)a = (ga)b.
Les valeurs a et b ne sont connues que de A et de B respectivement et ne circulent pas sur le réseau. Même si l’échange est intercepté, il sera très difficile de calculer (ga)b à partir de gb ou de ga.
L’avantage est que cette opération peut se répéter automatiquement et plusieurs fois au cours d’un échange, de manière à changer de clé avant qu’elle ne soit éventuellement cassée.
Les autres algorithmes sont moins répandus, soit parce qu’ils sont moins efficaces (exemple de SKIP), soit parce qu’ils sont encore trop complexes à mettre en œuvre ou encore parce que trop récents, ce qui est le cas de ECSVAP1.
La gestion des certificats
Les algorithmes symétriques posent le problème de l’échange préalable des clés secrètes.
Les algorithmes asymétriques n’ont pas ce type de problème, car la clé publique est connue de tous. Cela soulève cependant un autre point : est-on certain que la clé publique est bien celle de la personne à qui l’on veut envoyer un message ?
Les clés publiques sont, en effet, hébergées sur des serveurs, qui sont donc susceptibles d’être piratés. Pour contourner l’obstacle, le destinataire peut communiquer sa clé publique à qui la demande, mais on retombe dans les difficultés liées à la diffusion des clés symétriques.
L’autre solution consiste à certifier la clé auprès d’une autorité au-dessus de tout soupçon, appelée CA (Certificate Authority). L’émetteur A désirant envoyer un message à B demande au serveur de certificats de confirmer que la clé publique dont il dispose, est bien celle de B :
- A demande un certificat pour la clé publique de B.
- Le CA utilise sa clé privée pour signer la clé publique de B : cette signature constitue le certificat.
- A vérifie la signature avec la clé publique du CA.
Mais comment être certain que la clé publique du CA est bien la sienne ? Le problème subsiste en effet. On peut alors désigner une autorité qui certifierait les CA, un gouvernement ou un organisme indépendant, par exemple. Aux États-Unis, les CA habilités à émettre des certificats sont VeriSign, Entrust, RSA. En France, la DCSSI (Direction centrale de la sécurité des systèmes d’information) a habilité des sociétés telles que CertPlus, CertEurope ou Certinomis ainsi que des filiales spécialisées créées par des banques françaises (cf. http://www.minefi.gouv.fr/dematerialisation_icp/dematerialisation_declar.htm).
Le standard en matière de certificats est X.509 de l’ISO repris dans le RFC 1422. Il est utilisé par les navigateurs Web via SSL, les annuaires LDAP (Lightweight Directory Access Protocol) ou encore par le SET (Secure Electronic Transaction) pour le paiement électronique.
Les serveurs qui gèrent, distribuent et valident les certificats sont appelés PKI (Public Key Infrastructure). Pour plus de détails, le lecteur pourra se référer au site www.pki-page.org.
La signature numérique
La signature numérique permet de prouver que l’émetteur du message est bien celui qu’il prétend être. Une fonction de hachage est opérée sur le message, et la valeur obtenue (le digest) est chiffrée avec la clé privée de l’émetteur. Tous les destinataires peuvent vérifier que l’émetteur est bien celui qu’il prétend être en déchiffrant la valeur de hachage avec la clé publique de l’émetteur et en la comparant avec la valeur calculée sur le message reçu, à l’aide de la même fonction de hachage.

Pour ce type d’algorithme, on trouve :
- DSA (Digital Signature Algorithm) qui repose sur le standard DSS (Digital Signature Standard) du NIST (National Institute of Standard and Technologies), et utilise une clé privée à 1024 bits et un algorithme basé sur le log de Zp analogue à Diffie-Hellman.
- ECDSA (Elliptic Curve de DSA) qui est analogue à DSA mais se base sur un algorithme ECC.
- Rabin Digital Signature qui repose sur la racine carrée des nombres modulo Zn où n est le produit de 2 grands nombres premiers : la racine carrée de Zn est difficile à trouver (la racine carrée de X modulo Zn est très difficile à trouver quand on ne connaît pas n).
L’enveloppe numérique
L’enveloppe numérique est une technique de plus en plus utilisée. On la trouve dans PGP, Mime, PEM (Privacy Enhanced Mail). Le principe est le suivant :
- Le message est chiffré à l’aide d’un algorithme à clé secrète tel IDEA ou CAST.
- La clé secrète est à son tour chiffrée à l’aide d’un algorithme à clé publique tel RSA.
- Les destinataires déchiffrent la clé secrète à l’aide de leur clé privée.
- La clé secrète ainsi déchiffrée est utilisée pour déchiffrer le message.
Par exemple, PGP peut utiliser IDEA 128 bits pour chiffrer le message et RSA, 1 024 bits pour chiffrer la clé IDEA.
Les algorithmes à clé publique sont plus puissants que les algorithmes à clé symétrique : ils sont, de ce fait, plus lents et soumis à de plus grandes restrictions d’utilisation et d’exportation. L’intérêt de la technique de l’enveloppe est qu’elle permet de protéger la clé de chiffrement avec un algorithme réputé inviolable, et d’utiliser un algorithme moins puissant mais plus rapide pour chiffrer le message.
Les contraintes législatives
En France, la DCSSI (Direction centrale de la sécurité des systèmes d’information) autorise une utilisation libre de tous les algorithmes d’authentification, de signature et de contrôle d’intégrité, quelle que soit la longueur de leur clé.
En ce qui concerne le chiffrement, l’utilisation est libre dès lors que la longueur de clé n’excède pas 128 bits, et que le logiciel ait été déclaré à la DCSSI par le fournisseur. Audelà de cette longueur, le chiffrement est soumis à autorisation, à moins que la clé soit gérée par un tiers de confiance agréé par la DCSSI et susceptible de remettre les clés aux autorités judiciaires et de sécurité, à leur demande.
Toute exportation d’un moyen de chiffrement doit faire l’objet d’une déclaration à la DCSSI. Le site www.ssi.gouv.fr permet de consulter les textes les plus à jour.
Le chiffrement des données
Les VPN IPsec (Virtual Private Network – IP security), cités au chapitre 10, consistent à créer un tunnel IP chiffré entre un PC isolé et un site (mode Client-to-LAN) ou entre deux sites (mode LAN-to-LAN). Le terme de VPN est donc (un peu) usurpé, car le réseau privé virtuel ne repose pas sur un partitionnement logique du réseau d’un opérateur, mais sur le chiffrement des données. Il est d’ailleurs possible d’utiliser IPsec au-dessus d’un VPN de niveau 2 ou de niveau 3 (cf. chapitre 10) et de toute liaison WAN ou LAN en général. La notion de VPN appliquée à IPsec ne vient qu’avec le chiffrement des données ; il est donc possible de créer un réseau privé au-dessus d’Internet, qui est un réseau public résultant de la concaténation de réseaux opérateur (cf. annexes).
D’une manière générale, le chiffrement permet de renforcer la sécurité pour les données sensibles circulant dans un domaine de non-confiance. Si le niveau de sécurité l’exige, il peut s’appliquer :
- aux accès distants qui empruntent le réseau téléphonique d’un opérateur (mode PC-to-LAN) ;

- ou entre deux sites interconnectés par un réseau opérateur, que ce soit une LS, un VPN de niveau 2 ou 3 ou encore Internet (mode LAN-to-LAN) ;

ƒ et, éventuellement, entre deux PC ou serveurs de notre réseau, qu’il soit de type LAN, MAN, WAN ou WLAN.
La fonction VPN peut être intégrée ou non dans le firewall.
LE POINT SUR IPSEC (RFC 2401, 2402, 2406)
Le protocole IPsec permet de chiffrer et de contrôler l’intégrité des données, soit de bout en bout (mode transport), soit sur une portion du réseau (mode tunnel), ainsi que d’authentifier l’émetteur. Pour ce faire, le paquet IP est encapsulé dans un paquet ESP (Encapsulation Security Payload – RFC 2406).

Le mode transport est utilisé entre un client et un serveur pour protéger les données transportées dans le paquet IP originel, mais pas l’entête IP lui-même. Le mode tunnel est, quant à lui, utilisé si l’une des deux extrémités au moins est un firewall ou un boîtier IPsec : il permet de chiffrer entièrement le paquet IP originel, l’entête et ses données. Il est à noter qu’il est possible d’encapsuler le mode transport dans le mode tunnel afin, par exemple, de chiffrer entièrement et de bout en bout le paquet IP original, tout en traversant des firewalls. L’inverse est également possible afin, par exemple, de masquer à un réseau tiers tel qu’Internet le plan d’adressage interne à l’entreprise.
Un autre type d’encapsulation, appelé AH (Authentication Header - RFC 2402), offre les mêmes fonctionnalités hormis le chiffrement des données. Il est très peu utilisé.
La taille maximale des données transportées dans un paquet IP est définie par le MTU (Maximum Transfer Unit) de la couche sous-jacente (par exemple, 1 500 octets pour Ethernet). Si le paquet IP est déjà au maximum de son MTU, l’overhead ajouté par IPsec provoque systématiquement l’activation du mécanisme de fragmentation IP (cf. chapitre 5).
Les sessions IPsec, appelées security associations, sont initiées et gérées à l’aide du protocole IKE (Internet Key Exchange – RFC 2409), qui s’appuie sur les procédures ISAKMP (Internet Security Association and Key Management Protocol – RFC 2408), Oakley et Skeme. Les algorithmes d’authentification, de chiffrement et de contrôle d’intégrité, ainsi que les longueurs de clés, sont à cette occasion négociés. Selon le sélecteur retenu, deux nœuds peuvent établir une session IPsec, soit pour l’ensemble de leurs échanges, soit pour chaque couple d’adresses IP et/ou de port TCP/UDP.
L’authentification
L’authentification apporte une protection supplémentaire par rapport à la connexion par mot de passe classique, car celui-ci, même s’il est chiffré, circule entre le client et le serveur. Intercepté et déchiffré, il peut donc être réutilisé par un éventuel pirate. De plus, comme il ne change pas d’une session à l’autre, la session interceptée peut être rejouée sans avoir besoin de déchiffrer le mot de passe.
L’authentification consiste donc à s’assurer que l’émetteur est bien celui qu’il prétend être. Ce type de protection peut aussi bien s’appliquer à des utilisateurs qu’à des protocoles réseau tels qu’OSPF, afin de s’assurer que seuls les routeurs dûment identifiés soient habilités à échanger des informations de routage.
Les mécanismes d’authentification
La connexion d’un utilisateur sur un ordinateur implique la saisie d’un nom de compte et d’un mot de passe. Deux mécanismes de protection sont mis en œuvre à cette occasion :
- le chiffrement du mot de passe à l’aide d’un algorithme quelconque ;
- la génération d’un mot de passe différent à chaque tentative de connexion.
Le premier mécanisme utilise les algorithmes classiques symétriques et asymétriques. Le deuxième mécanisme, appelé One Time Password, peut être réalisé de deux manières :
- par défi/réponse (challenge/response) ;
par mot de passe variant dans le temps à l’aide de calculettes appelées token cards.
Il existe beaucoup de produits qui utilisent des variantes. Parmi les plus représentatifs, on trouve :
- CHAP (Challenge Handshake Authentication Protocol – RFC 1994), mécanisme logiciel ;
- S/Key (RFC 1938), mécanisme logiciel ;
- Secure ID (Security Dynamics), calculette ;
- ActivCard (société française), calculette, clé USB ou logiciel ;
- Access Master de Bull, carte à puce CP8.
Le protocole CHAP (Challenge Handshake Authentication Protocol) est utilisé en conjonction avec PPP (cf. chapitre 9) pour les accès distants. C’est un mécanisme d’authentification qui offre un premier niveau de sécurité :
- Le serveur envoie un challenge aléatoire.
- Le client répond avec un hachage MD5 opéré sur la combinaison d’un identifiant de session, d’un secret et d’un challenge.
Le secret est un mot de passe connu du logiciel client et du serveur.
L’authentification de CHAP repose donc sur une clé secrète et un algorithme de hachage. Le mot de passe ne circule pas sur le réseau mais doit être codé en dur sur le logiciel client et le serveur. Sur un serveur Radius, ce mot de passe peut même être inscrit en clair dans la base de données.
Le mécanisme S/Key de Bellcore repose également sur l’algorithme de hachage MD5 appliqué à une liste de mots de passe valables pour une seule tentative de connexion :
Le mécanisme S/Key de Bellcore repose également sur l’algorithme de hachage MD5 appliqué à une liste de mots de passe valables pour une seule tentative de connexion :
- La liste des clés est générée à partir d’une clé initiale : la clé N s’obtient en appliquant MD5 à la clé N-1 et ainsi de suite.
- Le serveur qui connaît la clé N+1 demande la clé N (codée à partir de la clé initiale).
- Soit l’utilisateur possède la liste des clés codées, soit il utilise un programme qui la génère à la demande à partir de la clé initiale.
- Le serveur applique MD5 à n et le résultat est comparé avec la clé N+1.
- Le serveur enregistre la clé n et demandera la prochaine fois la clé N-1.
- Arrivé à la clé 1, il faudra régénérer une nouvelle liste.
Le problème de S/Key est la gestion de cette liste. De plus, il est relativement facile de se faire passer pour le serveur (technique du spoofing) :
- Le vrai serveur demande la clé N à l’utilisateur.
- Le faux serveur détourne la communication et demande la clé N-10 à l’utilisateur.
- L’utilisateur consulte sa liste (ou génère la clé) et renvoie la réponse au faux serveur.
- Disposant de la clé N-10, il suffit alors d’appliquer MD5 à N-10 pour obtenir la clé N-9, et ainsi de suite.
- Il suffit alors de lancer MD5 de 2 à 10 fois sur cette clé pour obtenir les réponses pour les clés N-1 à N-10 que le vrai serveur demandera aux prochaines demandes de connexion.
La calculette SecureID repose cette fois sur un microprocesseur qui génère un mot de passe temporel toutes les 60 secondes. Celui-ci dérive de l’horloge et d’une clé secrète partagée par la carte et le serveur :
- L’utilisateur saisit son PIN (Personnal Identification Number) sur sa carte.
- La carte génère un mot de passe en fonction du temps et de la clé secrète (seed) contenue dans la carte.
- L’utilisateur envoie au serveur le mot de passe affiché par la carte.
- Le serveur génère en principe le même mot de passe et compare la réponse avec son propre calcul.
Le serveur doit cependant tenir compte du décalage de son horloge avec celle de la carte.
Fonctionnement d’une calculette d’authentification
La clé 3DES utilisée par la calculette ActiveCard est une combinaison de plusieurs clés :
- une clé secrète « organisation », commune à plusieurs utilisateurs ;
- une clé secrète « ressource » propre à une application, à une machine sur laquelle on veut se connecter, à une utilisation particulière de la calculette ;
- une clé « utilisateur » qui est le nom de l’utilisateur, le nom d’un compte, ou un identifiant quelconque propre au propriétaire de la calculette.
La clé ressource désigne une machine cible sur laquelle on veut se connecter ou toute autre application (par exemple, « Accès distants »). Dix ressources sont ainsi programmables sur la calculette, ce qui veut dire que l’on peut utiliser la carte pour se connecter à dix machines différentes. Pour la version logicielle, ce nombre est illimité.
La calculette génère des clés sur la base d’informations prédéfinies (les trois clés précédemment citées, l’identifiant de l’utilisateur et le numéro de série de la calculette), et sur la base d’une information variable qui est un compteur. Les informations statiques sont stockées dans la calculette et dans la base de données du serveur.
À chaque connexion, le compteur du serveur d’authentification s’incrémente de N. De même, à chaque fois que l’utilisateur appuie sur la touche de fonction ressource, la calculette incrémente son compteur interne de N. Les deux compteurs, ceux de la calculette et du serveur, doivent être synchronisés. Si l’utilisateur appuie trop de fois sur la touche de fonction par inadvertance, les deux compteurs peuvent être désynchronisés, ce qui empêche l’utilisateur de s’authentifier.
Dès qu’il reçoit le mot de passe, le serveur procède au même calcul et compare les résultats. S’ils sont identiques, il renvoie une autorisation. Afin de prendre en compte les éventuels écarts avec le compteur de la calculette, il procède à ce calcul avec les N/2 prochaines valeurs de son compteur et avec les N/2 précédentes.
Ce principe de fonctionnement est le même que celui utilisé par les commandes d’ouverture à distance des portes de voiture.
Les serveurs d’authentification
Pour sécuriser la connexion à un ordinateur, il existe, on vient de le voir, une multitude de techniques et de produits différents. Ces produits ne sont pas disponibles sur toutes les plates-formes, car le travail d’intégration est important.
Afin de pallier à cette difficulté, il est possible d’ajouter une couche supplémentaire en intercalant un serveur entre le client et la machine cible. Les éditeurs de systèmes d’authentification n’ont alors plus qu’à développer une seule interface avec le serveur de sécurité, et les machines cibles n’ont qu’à supporter un seul protocole d’authentification avec le serveur d’authentification.
Il existe trois grands standards sur le marché.

Radius est le plus utilisé. Kerberos a été le premier standard en la matière, mais sa mise en œuvre trop complexe a freiné son utilisation. Le support de Kerberos par Windows 2000 pourrait annoncer cependant la résurgence de ce standard qui n’a jamais réellement percé.
Tacacs est plus simple mais présente trop de lacunes. Tacacs+ a été développé par Cisco mais n’est pas réellement un standard.
Exemple d’authentification forte pour les accès distants
Les accès des utilisateurs depuis l’extérieur de l’entreprise, qu’ils soient nomades ou sédentaires, sont particulièrement dangereux, car ce type de besoin nécessite l’accès aux ressources de l’entreprise depuis un domaine de non-confiance. En plus du contrôle de flux réalisé par un firewall, il est nécessaire d’authentifier les utilisateurs, un peu à la manière d’une banque avec les cartes à puce.
Une première amélioration a été apportée par le système d’authentification CHAP lors de la connexion PPP entre le client et le serveur d’accès distants. Ce mécanisme ne suffit cependant pas, car il repose sur le partage d’un secret entre l’utilisateur et le serveur. Il est préférable d’utiliser un mécanisme d’authentification « fort » fondé sur des calculettes. Chaque calculette appartient à son détenteur, et tout comme une carte bancaire, son utilisation peut être associée à la saisie d’un code personnel.
Ce type de système repose sur un serveur Radius et, au choix, de calculettes hardwares et logicielles installées sur les postes de travail. Ce serveur est situé sur le réseau interne ou sur un segment dédié, et dialogue avec le firewall ou le serveur d’accès distants, installé sur un autre segment dédié. Il est également utilisé comme station d’administration permettant de configurer et d’activer les calculettes.

La solution mise en œuvre est indépendante du serveur d’accès distants et du mécanisme d’authentification. Il y a en fait deux niveaux d’authentification :
1. Au niveau PPP, entre le PC client et le serveur d’accès distants (via CHAP), permettant d’avoir accès au service réseau. Cette étape est transparente pour l’utilisateur à partir du moment où le mot de passe est stocké dans le poste de travail client.
2. Au niveau du firewall, entre le PC client et le serveur d’authentification (à l’aide des calculettes), permettant d’accéder à notre réseau intranet. Cette étape nécessite que l’utilisateur saisisse le mot de passe affiché sur la calculette.
La procédure de connexion qui en résulte est la suivante :
- Lors de la connexion, le PC envoie le mot de passe au serveur d’accès distants via le protocole CHAP. Vous utilisez le même mécanisme pour vous connecter à Internet avec votre modem RTC ou ADSL.
- Le firewall intercepte le premier paquet issu du PC. Il demande alors le nom de l’utilisateur. Celui-ci le saisit.
- Le firewall demande ensuite le mot de passe. L’utilisateur doit alors saisir son code d’identification sur la calculette ou sur son PC, s’il s’agit d’une clé USB ou d’une carte à puce connectée au PC via un lecteur.
- La calculette affiche alors un code constitué de chiffres et de lettres, que l’utilisateur saisit tel quel comme mot de passe. S’il s’agit d’une clé USB ou d’une carte à puce, l’utilisateur n’a rien à faire.
- Le firewall transmet les informations (nom de l’utilisateur et mot de passe) au serveur d’authentification via le protocole Radius.
- Le serveur d’authentification vérifie les informations par rapport à sa base de données et donne ou non l’autorisation au firewall (toujours via Radius).
Le mot de passe a été transmis du PC client au serveur d’authentification. Mais cela n’est pas grave puisqu’il n’est pas rejouable : celui qui l’intercepterait ne pourrait pas le réutiliser, car il n’est valable qu’une fois.
L’intérêt d’opérer l’authentification au niveau du firewall plutôt qu’au niveau du serveur d’accès distants est multiple :
- L’authentification permet de créer des règles de filtrage par nom utilisateur, indépendamment de leurs adresses IP.
- Le firewall enregistre dans son journal toutes les sessions des utilisateurs identifiés par leur nom.
- La politique de sécurité est implémentée et exploitée en un point unique, à partir de la console d’administration du firewall.
Avec ce principe, le serveur d’accès distants gère les connexions et les modems RTC ou ADSL, tandis que le firewall implémente la politique de sécurité de notre entreprise.
La gestion des calculettes (configuration, génération des codes secrets, etc.) est réalisée à partir d’une station d’administration, qui héberge également le serveur d’authentification Radius.
--------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------
Aucun commentaire:
Enregistrer un commentaire