
1- INTRODUCTION
Aujourd’hui, les entreprises tendent de plus en plus à vouloir utiliser les postes Dos/Windows présents dans
les bureaux pour faire tourner les applicatifs en plus des logiciels bureautiques. La première étape à consister à installer sur les micros des émulations permettant au micro de fonctionner comme un terminal classique de l’ordinateur central (gros système, AS400, Unix ou autre).
les bureaux pour faire tourner les applicatifs en plus des logiciels bureautiques. La première étape à consister à installer sur les micros des émulations permettant au micro de fonctionner comme un terminal classique de l’ordinateur central (gros système, AS400, Unix ou autre).
Le contraste entre l’ergonomie de Windows et des terminaux en mode texte a conduit à rechercher le moyen d’exécuter sous Windows des applications utilisant les données du site central. C’est ce que l’on a appelé l’architecture client/serveur.
Ce support de cours a pour but de définir précisément ce qu’est une architecture client/serveur, puis de préciser ce qu’est dans ce contexte un serveur de données, quel est son fonctionnement et enfin comment il dialogue avec les clients.
Les concepts présentés ici sont suffisamment généraux pour être communs à tous les serveurs de données actuels du marché : Oracle , Microsoft Sql Server , Sybase, Sql Anywhere, ....
2 - LE MODÈLE CLIENT/SERVEUR DE DONNEES
2.1 - Le concept de client/serveur
2.1.1 Définition
La définition d’une architecture client/serveur est la suivante :
Ensemble de machines pouvant communiquer entre elles, et s’échangeant des services : traitement, données ou ressources
Concrètement, il s’agit de plusieurs machines reliées par un réseau local ou étendu. Certaines de ces machines sont capables d’offrir des services, tels que l’exécution d’une procédure, la recherche de données, le partage d’une ressource : ce sont des serveurs.
D’autres vont utiliser ces services : ce sont les clients.
Si l’on s’en tient à la définition toute machine peut être client ou serveur ou les deux à la fois ou alternativement l’un puis l’autre.

2.1.2 Le schéma du Gartner Group
Un groupe d’étude composé d’acteurs du marché a défini 6 types d’architectures client/serveur, en considérant qu’une application de gestion quelle qu’elle soit se décompose en trois parties : présentation, traitements et données.
- Présentation (ou interface)
C’est à dire à la fois la définition du scénario de saisie et l’algorithme permettant d’interpréter les interactions de l’utilisateur, tel que l’API Windows
- Traitements
C’est à dire les algorithmes propres à l’application (calcul du montant de la facture, enchaînement des traitements, etc...) et des algorithmes réutilisables par plusieurs applications (tris, édition, calculs statistiques, etc...)
- Données
Il faut distinguer la logique des données, c’est à dire la vue logique des données utilisée par l’application et la gestion des données, c’est à dire tout le travail que fait le S.G.B.D. (recherche des données, stockage, contrôle des accès, etc...)

Sur ce schéma, le trait horizontal représente le réseau et les flèches entre client et serveur, le trafic réseau généré par la conversation entre client et serveur.
Le Gartner Group distingue les types de client-serveur suivants, en fonction du type de service déporté du cœur de l'application :
- Présentation distribuée : Correspond à l'habillage ``graphique'' de l'affichage en mode caractères d'applications fonctionnant sur site central. Cette solution est aussi appelée revamping. La classification "client-serveur'' du revamping est souvent jugée abusive, du fait que l'intégralité des traitements originaux est conservée et que le poste client conserve une position d'esclave par rapport au serveur.
- Présentation distante : Encore appelée client-serveur de présentation. L'ensemble des traitements est exécuté par le serveur, le client ne prend en charge que l'affichage. Ce type d'application présentait jusqu'à présent l'inconvénient de générer un fort trafic réseau et de ne permettre aucune répartition de la charge entre client et serveur. S'il n'était que rarement retenu dans sa forme primitive4.1, il connaît aujourd'hui un très fort regain d'intérêt avec l'exploitation des standards Internet.
- Gestion distante des données : Correspond au client-serveur de données, sans doute le type de client-serveur le plus répandu. L'application fonctionne dans sa totalité sur le client, la gestion des données et le contrôle de leur intégrité sont assurés par un SGBD4.2 centralisé. Cette architecture, de part sa souplesse, s'adapte très bien aux applications de type infocentre, interrogeant la base de façon ponctuelle. Il génère toutefois un trafic réseau assez important et ne soulage pas énormément le poste client, qui réalise encore la grande majorité des traitements.
- Traitement distribué : Correspond au client-serveur de traitements. Le découpage de l'application se fait ici au plus près de son noyau et les traitements sont distribués entre le client et le(s) serveur(s). Le client-serveur de traitements s'appuie, soit un mécanisme d'appel de procédure distante, soit sur la notion de procédure stockée proposée par les principaux SGBD du marché. Cette architecture permet d'optimiser la répartition de la charge de traitement entre machines et limite le trafic réseau. Par contre il n'offre pas la même souplesse que le client-serveur de données puisque les traitements doivent être connus du serveur à l'avance.
- Bases de données distribuées : Il s'agit d'une variante du client-serveur de données dans laquelle une partie de données est prise en charge par le client. Ce modèle est intéressant si l'application doit gérer de gros volumes de données, si l'on souhaite disposer de temps d'accès très rapides sur certaines données ou pour répondre à de fortes contraintes de confidentialité.
Ce modèle est aussi puissant que complexe à mettre en œuvre.
- Données et traitements distribués. Ce modèle est très puissant et tire partie de la notion de composants réutilisables et distribuables pour répartir au mieux la charge entre client et serveur.
C'est, bien entendu, l'architecture la plus complexe à mettre en œuvre.
2.2 - Le client/serveur de données
L'ARCHITECTURE DEUX TIERS

Dans une architecture deux tiers, encore appelée client-serveur de première génération ou client-serveur de données, le poste client se contente de déléguer la gestion des données à un service spécialisé. Le cas typique de cette architecture est l'application de gestion fonctionnant sous Ms-Windows et exploitant un SGBD centralisé.
Ce type d'application permet de tirer partie de la puissance des ordinateurs déployés en réseau pour fournir à l'utilisateur une interface riche5.1, tout en garantissant la cohérence des données, qui restent gérées de façon centralisée.
La gestion des données est prise en charge par un SGBD centralisé, s'exécutant le plus souvent sur un serveur dédié. Ce dernier est interrogé en utilisant un langage de requête qui, le plus souvent, est SQL..
Le dialogue entre client et serveur se résume donc à l'envoi de requêtes et au retour des données correspondant aux requêtes. Ce dialogue nécessite l'instauration d'une communication entre client et serveur.
2.2.1 - Le dialogue avec les clients
Le principe du dialogue entre clients et serveurs peut être schématisé ainsi :

Le client envoie une requête au serveur de données. Cette requête est :
- traduite dans un format compréhensible par le SGBD (API)
- formatée en une suite de trames compatibles avec le protocole réseau (FAP)
- véhiculée par le réseau jusqu’au serveur concerné
Sur le serveur l’opération inverse est effectuée :
- Recomposition de la requête à partir des trames reçues (FAP)
- Le SGBD interprète la requête et l’exécute
Le résultat de la requête prend ensuite le chemin inverse.
Le client provoque l'établissement d'une conversation afin de d'obtenir des données ou un résultat de la part du serveur.

Cet échange de messages transite à travers le réseau reliant les deux machines. Il met en oeuvre des mécanismes relativement complexes qui sont, en général, pris en charge par un middleware.
2.2.2 - Le rôle du serveur de données
Il est à l’écoute des requêtes provenant des clients. Il y répond en faisant appel aux fonctions d’un S.G.B.D. classique.
- Langage de Description de Données (L.D.D.)
Ce langage permet de décrire les données (Type, Longueur, Nature ...), les relations entre les données, les règles de gestion, les domaines de valeur, etc... En langage SQL c’est par exemple l’instruction CREATE ….
- Langage de Manipulation de Données (L.M.D.)
Ce langage sert à exécuter les opérations d’ajout, suppression, modification des données. Il permet également l’interrogation des données. C’est en général le langage utilisé dans les requêtes. En langage SQL c’est par exemple l’instruction SELECT ….
- Gestion du stockage
Le S.G.B.D organise le stockage des données sur disque. Cette organisation interne est transparente pour l’utilisateur et le programmeur. Il offre une vue logique des données.
- Partage des données
Dans ce contexte multi-utilisateurs, c’est le S.G.B.D. qui gère le partage des données entre les différents utilisateurs (ou clients) C’est lui qui en s’appuyant en général, sur le système d’exploitation évite les situations de conflit et les situations d’interblocage ou étreinte fatale.
- Confidentialité
Le S.G.B.D. assure la confidentialité des données : il contrôle les droits d’accès des utilisateurs. C’est à dire dans ce contexte des applications clientes lorsqu’elles demandent la connexion. (Voir 3.1.2)
- Sécurité, fiabilité, cohérence
Le S.G.B.D. assure la sécurité des données. C’est à dire qu’il doit veiller à ce que les données restent cohérentes. Par exemple il doit faire en sorte qu’une commande ne puisse pas être créée tant que toutes les lignes de commande ne sont pas créées, ou qu’un client ne soit pas supprimé sans avoir au préalable supprimé toutes les commandes attachées à ce client.
Dans les deux cas ci -dessus (création d’une commande ou suppression d’un client) il y a plusieurs actions consécutives à exécuter dans la base de données. Pour que la base de données reste cohérente, il faut que ces actions soient toutes exécutées ou alors aucunes.
L’ensemble de ces actions est appelé transaction.
Le S.G.B.D doit rendre les transactions interruptibles.
Si une interruption intervient au cours d’une transaction, le système remet les données dans l’état où elles étaient avant le début de la transaction.
- Sauvegarde et restauration
La sauvegarde et la restauration sont deux outils du S.G.B.D permettant de mémoriser puis de retrouver une base de données dans un état cohérent.
- Contrôle d’intégrité
La plupart des S.G.B.D offrent la possibilité de décrire les règles de gestion du système ’informations de l’entreprise. Par exemple, si un client n’existe pas, on ne peut pas lui associer de facture.
Une fois toutes les règles décrites, le S.G.B.D vérifie que les mises à jour effectuées sur les données respectent ces règles. Ainsi, il refusera la création de la facture tant que le client ne sera pas créé.
3 - GENERALITES SUR LES SERVEURS DE DONNEES
3.1 - La fonction serveur
Pour faire fonctionner une architecture client/serveur, il faut que le serveur soit à l’écoute des requêtes des clients.
Suivant les systèmes d’exploitation la terminologie employée diffère :
- Processus en background sous Unix
- Service sous Windows NT
Dans tous les cas, c’est une tâche de fond qui écoute les requêtes, c’est à dire en fait une fonction qui tourne tout le temps et scrute s’il y a des requêtes à traiter.
3.1.1 Dialogues à session
Dans un type de dialogue à session, le client et le serveur dialoguent de la manière suivante :
- La fonction serveur reçoit la demande de connexion, le S.G.B.D. vérifie les droits et crée le contexte
- la fonction serveur reçoit les requêtes et les transmet au S.G.B.D.
- le S.G.B.D. exécute les requêtes, transmet le résultat à la fonction serveur qui fait suivre.
3.1.2 Dialogues à messages
Dans un type de dialogue par messages toutes les demandes ainsi que les réponses sont stockées dans une file d’attente de messages.
Le système fonctionne en temps différé :
- La fonction serveur traite les requêtes de la file d’attente en FIFO et envoie ses réponses de la même manière
- Le client envoie ses requêtes dans la file d’attente et si besoin est se bloque en attente de recevoir la réponse, sinon il continue et traitera la réponse le moment venu en observant la file d’attente.
3.2 - Le serveur de traitements
La plupart des SGBD actuels offrent un SQL procédural. C’est à dire que l’on peut faire exécuter par le serveur une partie des traitements qui étaient jusque-là effectués sur le client :
- Vérification des règles de gestion (cohérence des informations entre plusieurs tables)
- Conversion (ou remplissage) automatique de certains champs avant l’insertion
- Transactions particulières indépendantes des applicatifs
- etc...
Ces procédures et triggers sont déclenchés par les applications qui tournent sur les postes clients, mais elles sont exécutées par le processeur du serveur.
Ce découpage a deux buts essentiels :
- assurer une meilleure répartition des traitements entre clients et serveur
- centraliser les règles de gestion pour une meilleure cohérence de la base de données
- Les règles ont écrites une fois pour toutes;
3.2.1 Les triggers (ou déclencheurs)
Ce sont des points d’entrée auxquels on peut accrocher du code SQL. Ces points d’entrée sont propres à chaque table et permettent d’agir à trois moments :
- À l’insertion d’un enregistrement
- À la suppression d’un enregistrement
- À la modification d’un enregistrement
Exemples d’utilisation:
- Ajout d’informations avant insertion
Une règle de gestion indique que si le montant de la facture est inférieur à 1000F, il faut facturer des frais de port d’une valeur de 49F. Cette règle peut être exécutée par les applications clientes directement. Mais pour éviter les erreurs et les redondances on peut créer un trigger sur insertion dans la table facture.
Le code serait le suivant :
Sur insertion dans facture
Si montant < 1000
Alors port = 49
Sinon port = 0
FSI
Valider l’insertion (commit)
- Contrôle de cohérence entre plusieurs tables
Une règle de gestion dans une bibliothèque étudiante indique qu’un étudiant ne peut pas emprunter d’ouvrages tant qu’il n’est pas à jour de ses règlements avec la comptabilité.
On ajoutera dans ce cas un trigger sur insertion dans la table emprunt.
Le code serait le suivant :
Sur insertion dans emprunt
Rechercher dans la table compta
Le solde de l’étudiant dont le no d’adhérent
Est celui pour lequel on veut faire l’insertion
Si solde <> 0
Alors annuler l’insertion
Sinon valider l’insertion
FSI
Soit en SQL
SELECT solde from adherent, compta, emprunt
WHERE adherent.no = emprunt.noadh
AND compta.nom = adherent.nom
IF solde = 0 THEN commit ELSE rollback
- suppressions en cascade
On souhaite lorsque l’on supprime un client supprimer toutes les informations qui lui sont attachées (commande, facture, règlements)
On va créer un trigger sur suppression dans la table client
Le code SQL serait le suivant :
Sur suppression dans client
DELETE FROM commande
WHERE commande.nocli = nocli
Les commandes étant attachées aux lignes de commande on est obligé d’ajouter un autre trigger sur la table commande
Sur suppression dans commande
DELETE FROM lignes_commande
WHERE lignes_commande.nocde = nocde
3.2.2 Les procédures stockées
Elles permettent de constituer des catalogues de procédures SQL accessibles depuis n’importe quelle application, que ce soit en client/serveur ou sur le serveur lui-même, ou même dans les triggers.
Ces procédures sont écrites en SQL Procédural et sont alors exécutées par le processeur du serveur.
4 - DIALOGUE AVEC LES CLIENTS.
4.1 - Le “ Middleware ”
Définition
On appelle middleware, littéralement ``élément du milieu'', l'ensemble des couches réseau et services logiciel qui permettent le dialogue entre les différents composants d'une application répartie. Ce dialogue se base sur un protocole applicatif commun, défini par l'API du middleware.
API : Application Programming Interfaces, ou interface de programmation du niveau applicatif, encore appelée protocole applicatif. L'API prend en charge l'interface entre le programme et le système.
Le Gartner Group définit le middleware comme une interface de communication universelle entre processus. Il représente véritablement la clef de voûte de toute application client-serveur.
L'objectif principal du middleware est d'unifier, pour les applications, l'accès et la manipulation de l'ensemble des services disponibles sur le réseau, afin de rendre l'utilisation de ces derniers presque transparente.

Les services rendus
Un middleware est susceptible de rendre les services suivants
- Conversion : Service utilisé pour la communication entre machines mettant en œuvre des formats de données différents, elle est prise en charge par la FAP
- Adressage : Permet d'identifier la machine serveur sur laquelle est localisé le service demandé afin d'en déduire le chemin d'accès. Dans la mesure du possible, cette fonction doit faire appel aux services d'un annuaire.
- Sécurité : Permet de garantir la confidentialité et la sécurité des données à l'aide de mécanismes d'authentification et de cryptage des informations.
- Communication : Permet la transmission des messages entre les deux systèmes sans altération. Ce service doit gérer la connexion au serveur, la préparation de l'exécution des requêtes, la récupération des résultats et la déconnexion de l'utilisateur.
Le middleware masque la complexité des échanges inter-applications et permet ainsi d'élever le niveau des API utilisées par les programmes. Sans ce mécanisme, la programmation d'une application client-serveur serait extrêmement complexe et rigide.
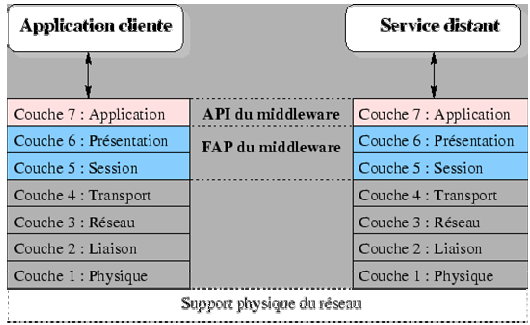
Le middleware par rapport au modèle OSI (Open Systems Interc onnection)
Exemples de middleware
- SQL*Net : Interface propriétaire permettant de faire dialoguer une application cliente avec une base de données Oracle. Ce dialogue peut aussi bien être le passage de requêtes SQL que l'appel de procédures stockées.
- ODBC (Open DataBase Connectivity): Interface standardisée isolant le client du serveur de données. C'est l'implémentation par Microsoft du standard CLI (Call Level Interface) défini par le SQL Access Group. Elle se compose d'un gestionnaire de driver standardisé, d'une API s'interfaçant avec l'application cliente (sous Ms Windows) et d'un driver correspondant au SGBD utilisé.
- DCE (Distributed Computing Environment) : Mécanisme de RPC proposé par l'OSF: Permet l'appel à des procédures distantes depuis une application.
Le choix d'un middleware est déterminant en matière d'architecture, il joue un grand rôle dans la structuration du système d'information.
Les middleware proposés par les fournisseurs de SGBD sont très performants et permettent de tirer profit de l'ensemble des fonctionnalités du serveur de données pour lequel ils ont été conçus. Par contre, ils ne permettent pas, le plus souvent, l'accès à d'autres sources de données.
Pour certaines applications devant accéder à des services hétérogènes, il est parfois nécessaire de combiner plusieurs middlewares. Dans ce cas, le poste client doit connaître et mettre en oeuvre plusieurs IPC (Inter Process Communication), on en vient à la notion de client lourd.
Pour pallier à ces inconvénients un standard a été défini:
- ODBC (Open DataBase Connectivity) par Microsoft allié à d’autres intervenants du marché
4.2 - ODBC
4.2.1 Principe
Le client envoie une requête au serveur de données.
- Cette requête concerne une source de données définie par l’outil de configuration ODBC
- l’API ODBC recherche sa définition dans la base ODBC (quel type de SGBD, quel serveur, quelle database, ...) et la formate en trames compatibles avec le SGBD et la couche transport
- la requête est véhiculée par le réseau jusqu’au serveur concerné
Sur le serveur l’opération inverse est effectuée :
- recomposition de la requête à partir des trames reçues (FAP)
- le SGBD interprète la requête et l’exécute Le résultat de la requête prend ensuite le chemin inverse.
4.2.2 Concrètement
ODBC est un produit de Windows q ui comporte plusieurs parties :
- un outil de configuration
- des drivers (DLL) fournis par les S.G.B.D. cibles
- une API sous forme de DLL
Par l’intermédiaire de l’outil de configuration, on installe les drivers des S.G.B.D. qui sont appelés pilotes.
Ensuite on définit des sources de données.
Une source de données définit l’accès à une base de données sur un serveur de données. Pour cela on choisit un pilote et en fonction de celui -ci on entre les caractéristiques voulues.
4.3 - La structure des applications
4.3.1 connexion
Pour accéder à une base de données distante, l’application doit se connecter. Il faut songer que pour le SGBD cible, l’opération de connexion est coûteuse en ressource mémoire (création d’un contexte, vérification des droits)
Par conséquent, sauf ca s particuliers il ne faut maintenir la connexion que le temps nécessaire.
4.3.2 requêtes
Chaque requête sur les données est envoyée au serveur, donc elle transite par le réseau. Par conséquent elle est coûteuse, il faudra donc essayer d’en minimiser le nombre et la fréquence.
4.3.3 transactions
La notion de transaction en client/serveur est la même que sur un SGBD classique.
Elle revêt ici beaucoup plus d’importance car les incidents sont plus fréquents (incident du serveur, du réseau, du poste client, de Windows, de l’application, ...)
5 - OPTIMISATION DES APPLICATIONS CLIENT/SERVEUR
Pour améliorer les performances d’une application client/serveur, il faut considérer successivement tous les éléments qui entrent en jeu dans le temps de réponse de l’application :
- la puissance du poste client (mémoire, OS, vitesse du processeur, ...)
- la vitesse du réseau
- l’activité du réseau
- le middleware utilisé
- la puissance du serveur (mémoire, activité, puissance de la machine, du SGBDR,...)
- la répartition des traitements entre le c lient et le serveur
- la conception de l’application
- le code même de l’application (écriture des requêtes)
Il faut toutefois être conscient que le temps de réponse varie d’un instant à l’autre, que l’on ne peut pas toujours améliorer significativement les choses, que l’amélioration des performances ne doit pas se faire au détriment de la maintenabilité, qu’il suffit parfois de changer la conception de l’interface graphique pour que l’utilisateur ait l’impression que les choses vont mieux, bref que la tâche n’est pas simple !
5.1 - Déterminer la ou les causes du problème
Les mauvaises performances d’une application se ressentent essentiellement au niveau du poste client. En général, on constate les dégradations de performance sur un ou deux formulaires particuliers. On fera donc les tests en isolant ce formulaire dans une petite application de test.
- La cause peut en être le poste lui-même. Pour le vérifier, le plus simple si on le peut, est de tester l’application sur un poste plus puissant : si le résultat est meilleur c’est qu’une partie du problème vient de là.
- On peut également essayer de développer la même application en utilisant des données locales (sous Access par exemple). Si le temps de réponse devient bon, on peut de suite déduire que le problème vient du serveur ou du réseau. S’il est toujours mauvais on ne peut directement conclure, car on ne sait pas si la cause est le poste, l’outil de développement, ou le SGBD local.
- On peut reproduire les mêmes fonctionnalités avec un outil de développement différent, si le résultat est bien meilleur on en déduira soit que l’outil utilisé n’est pas performant soit que l’application a été mal programmée.
- On fera des essais lorsque le serveur est inactif (sa seule tâche sera de répondre à mon application) et lorsque le serveur est très actif (lancer différentes tâches sur le serveur, lancer l’applicatif concurremment sur plusieurs postes clients). Si les résultats sont sensiblement égaux on pourra en déduire que l’impact de la puissance du serveur sur le temps de réponse est négligeable.
- De même on fera des essais lorsque le réseau est inactif (le seul poste connecté est mon poste client) et lorsque le serveur est très actif (il y a beaucoup de postes connectés, lancer l’applicatif concurremment sur plusieurs postes clients). Si les résultats sont sensiblement égaux on pourra en déduire que l’impact de la vitesse et de l’activité du réseau sur le temps de réponse est négligeable.
5.2 - Les points à tester dès la phase de conception
Dès la phase de conception il est judicieux de prévoir la puissance des postes clients, du réseau et du serveur adéquats pour faire tourner l’application.
Pour cela, dès la conception on peut isoler les formulaires qui risquent a priori d’être coûteux en temps de réponse et faire les tests cités plus haut.
On pourra également avant de faire un choix tester les performances respectives des outils de développement et des middleware sur un même exemple.
En particulier, le choix d’ODBC qui est plus lent ne se justifie pas si l’application accède à un seul serveur et qu’il n’est pas prévu de la porter dans un autre environnement.
Lorsque l’on a constaté que le problème vient de la puissance du serveur, il faut encore déterminer plus précisément au niveau du serveur d’où vie nt ce problème.
Le problème peut provenir du système d’exploitation : trop de tâches en cours par rapport à ce qu’il est capable de gérer. La solution consiste en général soit à agrandir l’espace de swapping (mémoire virtuelle) et/ou à rajouter de la mémoire vive. Certains systèmes permettent de configurer la machine de manière à ce qu’elle privilégie le multitâche par rapport à ses autres activités.
Ce peut être le SGBDR qui est en cause. Est -il configuré au mieux ? La base de données à laquelle mon application accède est-elle optimisée ? La répartition des données sur disque est-elle satisfaisante (disque morcelé ou trop plein) ? Les ressources systèmes nécessaires au SGBDR sont–elles disponibles (recommandations de l’éditeur du SGBDR) ? N’y a -t-il pas des tâches inutiles en cours ?
Se souvenir qu’une connexion d’une application cliente au serveur peut, suivant les systèmes, consommer beaucoup de ressources au niveau du système d’exploitation.
5.4 - La répartition des traitements entre le client et le serveur
Si on a conclu que la puissance du serveur n’est pas en cause on essaiera de décharger l’application cliente en programmant le serveur.
Pour ce faire, on doit définir des triggers et/ou écrire des procédures stockées.
L’avantage est que dans les deux ca s, le code SQL correspondant est déjà compilé.
Le traitement d’une requête sur le serveur se déroule suivant les étapes :

Exemple1 :
On veut, dans une application, mettre à jour le champ CA (chiffre d’affaire) dans la table client à chaque fois qu’une commande est ajoutée pour ce client.
1er cas : l’application cliente envoie 2 requêtes
requête 1 : INSERT INTO commande VALUES (123, 2, “ 01/01/96 ”, 1240.00)
requête 2 : UPDATE client SET CA = CA + 1240.00 WHERE nocli = 2
Cela conduit à :
- requêtes sur le réseau
- pour chacune : analyse syntaxique, compilation, vérification des droits, exécution
2ème cas : on lance l’UPDATE par un trigger
Le client n’envoie qu’une requête (la requête 1)
Cela conduit à :
- réception de la requête du réseau
- analyse syntaxique
- compilation
- vérification des droits
- exécution
- exécution du trigger sur INSERT de commande
3ème cas : on écrit une procédure stockée qui fait les 2 opérations
Le client n’envoie qu’une requête (le lancement de la procédure)
Cela conduit à :
- réception de la requête du réseau
- vérification des droits et de l’existence de la procédure
- exécution
On peut donc penser que la meilleure solution est la 3ème. Cependant il faut considérer que dans ce cas, les opérations envisagées ont pour but de maintenir la cohérence dans la base de données.
Donc pour des raisons de maintenance, on choisira plutôt l’option 2
En effet, il faut comprendre que la mise à jour du CA doit être également effectuée lors de la suppression ou de la modification du montant d’une commande.
Si le montant de la commande à partir des lignes de commandes est calculé par un trigger, l’option 3 conduirait à écrire 3 procédures.
On aboutirait à :
- 1 trigger sur insert, delete, update de lignes de commande. Il lance l’update du montant de la commande et du CA du client
- 1 procédure pour insérer la commande, une procédure pour supprimer la commande, 1 procédure pour modifier la commande. Chacune mettant à jour le CA du client.
De plus, dans ce cas le code de l’application cliente risque d’y perdre en lisibilité, et on ne peut assurer qu’un programmeur utilise l’INSERT directement au lieu de la procédure.
Exemple2 :
On suppose qu’une entreprise souhaite faire une remise de 5% à tous les clients dont les commandes en cours ont un retard de livraison de plus de 2 jours.
Dans ce cas, on peut soit :
- lancer une requête qui recherche les commandes ayant un retard de livraison et calculer la remise et lancer la mise à jour dans l’application cliente
- écrire une procédure stockée pour faire ce travail
La meilleure solution sera alors la procédure.
Conclusion :
Il n’y a pas a priori de bonne ou de mauvaise solution. Chaque problème posé doit être étudié avec précision
5.5 - La conception de l’application
La façon dont sont conçus les formulaires et en particulier les contrôles de saisie influe également sur le temps de réponse de l’application.
5.5.1 Exemple 1 : minimiser le nombre de requêtes
On considère un formulaire de saisie des commandes, où il faudra saisir les coordonnées du client.
- 1er cas : on vérifie le code client saisi par l’utilisateur par une recherche dans la table. S’il existe on affiche ses coordonnées, sinon on ouvre un formulaire de saisie des nouveaux clients
- 2ème cas : on remplit une liste déroulante dans laquelle l’utilisateur est obligé de choisir, si le client n’existe pas il appuie sur un bouton qui ouvre le formulaire de saisie des nouveaux clients
Dans le 1er cas, la requête (SELECT * from CLIENT) est exécutée à chaque création de commande avec une recherche sur clé primaire.
Dans le 2ème cas, la requête (SELECT * from CLIENT) est exécutée une seule fois à l’ouverture du formulaire (et à chaque nouveau client) mais elle renvoit plus de données.
On préfèrera la 2ème solution car elle sollicite moins le réseau et le serveur.
5.5.2 Exemple 2 : travailler avec les données en mémoire
On considère un formulaire de consultation des commandes. Dans ce formulaire, il faudra afficher les infos des tables client, commande, lignes de commandes et articles. Un double clic sur le nom du client, permet d’ouvrir un formulaire visualisant le détail du client.
- 1er cas : sur double clic on ouvre le formulaire, sur ouverture du formulaire on fait un recherche dans la table client, on affiche le résultat.
- 2ème cas : sur double clic on ouvre le formulaire et on y affiche les données du client que l’on a récupéré lors de la jointure effectuée pour afficher la commande
Dans le 1er cas, on lance la requête (SELECT * from CLIENT WHERE nomcli= ‘xxxx’).
Dans le 2ème cas, la requête (SELECT * from CLIENT, commande, lignes_cde,produit) est exécutée une seule fois à l’ouverture du formulaire de saisie des commandes mais elle renvoit plus de données que dans le 1er cas.
On préfèrera la 2ème solution car elle sollicite moins le réseau et le serveur, à condition que le poste client ne soit pas trop juste en mémoire.
5.5.1 Exemple 3 : utiliser des vues
On considère un formulaire de consultation des commandes, dans ce formulaire, il faudra afficher les infos des tables client, commande, lignes de commandes et articles.
- 1er cas : on écrit la jointure dans l’application cliente
- 2ème cas : on définit une vue INFOCDE sur le serveur et on écrit dans l’application SELECT * FROM INFOCDE
Dans le 2ème cas, on gagne le temps d’analyse syntaxique et d’optimisation de la requête.
Conclusion
On pourrait multiplier les exemples, l’objectif de ce chapitre est de comprendre que la tâche d’optimisation d’une application client/serveur est complexe car il y a beaucoup de paramètres à prendre en compte.
Très intéressant
RépondreSupprimer