


Cours Codage des caractères - Code Ascii Code Ansi - Unicode avec des Exercices Corrigés
Table des Matières
Préambule
Introduction
La représentation des caractères
Le code Ascii
Le code Ascii étendu
Le code Ansi
L'Unicode
Exercices
Préambule
Traduisez ce message :


Vous avez compris ce message, mais en avez-vous compris le sens ?
1 Introduction
Comme vu précédemment, la représentation d'un message et donc de caractères peut prendre des formes bizarres. Dans le cours précédent, nous avons vu la codification des nombres, et surtout comment les ordinateurs manipulaient les données dans un langage qui leur était propre. Pour représenter les autres informations, nous avons besoin d'une symbologie standard qui prenne en compte :
Les lettres de l'alphabet 26
La différenciation majuscule, minuscule 26 de plus
Les chiffres 0 => 9 10
Les autres caractères (+ - * , ? @… )
Des caractères de commande (retour, dring…
… .
2 La représentation des caractères
Les lettres de l'alphabet 26
La différenciation majuscule, minuscule 26 de plus
Les chiffres 0 => 9 10
Les autres caractères (+ - * , ? @… )
Des caractères de commande (retour, dring…
… .
2 La représentation des caractères
2.1 Le code Ascii
En fait, la première codification a été liée au mode de transmission des données vers l'ordinateur. Les premiers ordinateurs étaient liés à des télétypes qui servaient de point d'entrée des données. Ces premiers systèmes étaient raccordés en liaison série sur les ordinateurs.
Les données étaient codées sur le système de base, à savoir l'octet.
Pour des raisons de fiabilités, cet octet a été séparé en 2 :
En fait, la première codification a été liée au mode de transmission des données vers l'ordinateur. Les premiers ordinateurs étaient liés à des télétypes qui servaient de point d'entrée des données. Ces premiers systèmes étaient raccordés en liaison série sur les ordinateurs.
Les données étaient codées sur le système de base, à savoir l'octet.
Pour des raisons de fiabilités, cet octet a été séparé en 2 :
- Les 7 bits de poids fort représentent la donnée
- Le bit de poids fort est réservé pour un contrôle de la donnée (bit de parité)
- Ce qui donne 128 possibilités
Ainsi est née la codification ASCII (American Standard Code for Information Interchange)
Chaque caractère est représenté par un code hexadécimal :
A ‰ 41H
B ‰ 42H
a ‰ 61H
…
De plus, la codification ASCII a respecté l'ordre de l'alphabet, ce qui permet de manipuler les données par leur codification et d'en effectuer un tri alphanumérique. Il est possible dans les logiciels d'utiliser le caractère ASCII ou le code correspondant.

TABLE DES CODES ASCII
2.2 Le code Ascii étendu
Certains constructeurs, dont IBM suivis par tous les fabricants de compatibles, ont enrichi cette table ASCII en utilisant le 8ème bit, ce qui double le nombre de caractères Représentables (256). Les caractères supplémentaires sont essentiellement :
- Les caractères accentués utilisés dans la langue française.
- Des jeux de caractères utilisés dans d'autres langues (≈,√,...).
- Quelques symboles mathématiques (?,—).
- Des caractères semi-graphiques qui permettent de réaliser des petits dessins géométriques (cadres, soulignés, etc..).
Le code ASCII 8 bits existe en 2 variantes : le jeu de caractères IBM PC (c‘est le jeu de caractères standard du DOS) et le jeu de caractères ISO-ANSI (jeu de caractères international utilisé dans Windows). Ces deux jeux diffèrent notamment au niveau des caractères nationaux accentués et des caractères semi-graphiques.
2.3 Le code Ansi
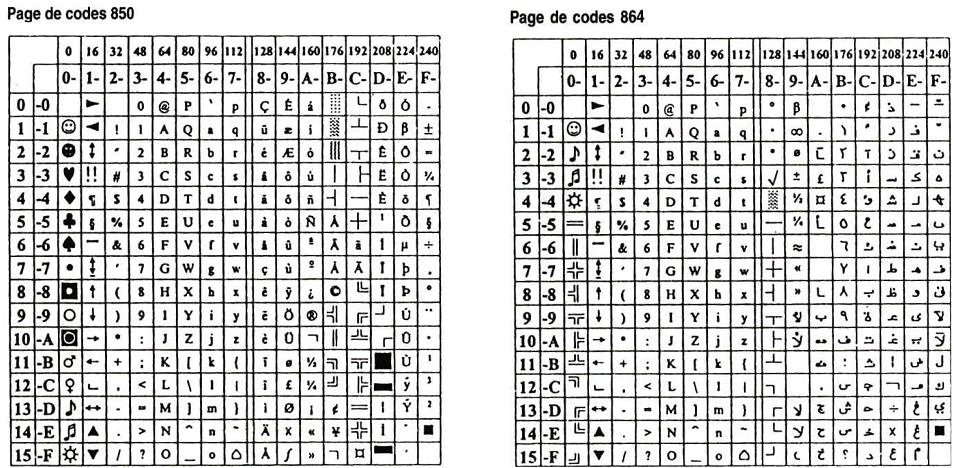
Les logiciels sous Windows utilisent la norme ANSI, qui reprend en grande partie le code ASCII, et propose des extensions différentes selon le « code de page » retenu.
Ainsi, le code page 850 est très employé en France, alors que le code page 864 définit un jeu de caractères « arabe ».
L‘utilisation du code ANSI se fait de la même manière que pour un code ASCII (intersections colonne-ligne).
2.4 L'Unicode
Compte-tenu de l‘extension mondiale de l‘informatique et de la diversité de plus en plus importante des caractères à stocker, les organismes de normalisation ISO travaillent depuis 1988 à la création d‘un code universel (UNIversal CODE). Ce code cherche à supprimer les pages de code et à reprendre l'ensemble des caractères utilisés de par le monde. Il reste basé sur la codification ASCII.
Il se représente sous 3 formes :
- UTF8 étant beaucoup utilisé sur Internet et présentant un codage de taille variable.
- UTF16 de taille fixe sur 2 octets ‰ Théoriquement 65 535 caractères différents.
- UTF32 sur 4 octets
En UTF8, tous les caractères de base ASCII 7 bits sont codés sur 1 octet. Au-delà, les caractères peuvent prendre de 2 à 4 octets.
Exemple :
Exemple :
3 Exercices :
1. Codez en ASCII :
Bienvenue Chez MrProof
2. Transcodez cette séquence :
4D 72 50 72 6F 6F 66 1 45 78 61 6D 65 6E 73 1 45 78 65 72 63 69 63 65 73 1 41 73 74 75 63 65 73
3. Repérez et décodez les séquences de texte. De quel type de fichier s'agit-il ?

4. Repérez et décodez les séquences de texte. De quel type de fichier s'agit-il ?

5. Repérez et décodez les séquences de texte. De quel type de fichier s'agit-il ?

6. Repérez et décodez les séquences de texte. Que remarquez-vous de particulier ?
Trouvez une explication

Correction des exercices
1-
42 69 65 6E 76 65 6E 75 65 1 43 68 65 7A 1 4D 72 50 72 6F 6F 66
2-
MrProof Examens Exercices Astuces
3-
Fichier Excel : Mon cahier de texte
4-
Fichier Image extension Gif
4-
Fichier Image extension Gif
5-
Un logiciel Exécutable (Winhex)
6-
Il s'agit d'un répertoire en NTFS
Les caractères sont codés sur 2 octets => Codage en UTF16
Il s'agit d'un répertoire en NTFS
Les caractères sont codés sur 2 octets => Codage en UTF16
Article plus récent Article plus ancien







