


Cours Système d'Analyse Merise : Approche Des Bases de Données SGBDR
7. APPROCHE DES BASES DE DONNEES.
7.1. Introduction.
7.1. Introduction.
Actuellement, on utilise les bases de données relationnelles plutôt que les fichiers pour développer des applications. La différence essentielle réside dans le fait que nos fichiers répondront à certaines conditions supplémentaires et que des relations relieront nos fichiers ( tables ). Nous parlerons de Système de Gestion de Bases de Données Relationnelles.
7.2. Représentation des données dans un SGBDR.
7.2.1. Exemple.
La représentation est assez simple : en voici un exemple :
Soit une entreprise qui a besoin de savoir quelles machine elle possède et où elles se trouvent et le responsable de l'atelier.
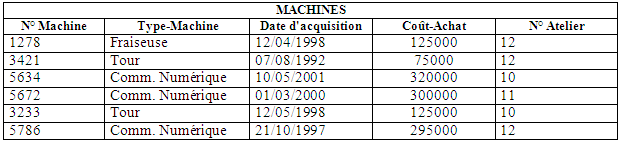

Nous avons deux listes : une pour les machines et une pour les ateliers. Remarquons que n° Atelier figure dans chaque liste. C'est ce numéro qui permettra la liaison entre les deux listes.
7.2.2. Vocabulaire.
Une base de données relationnelle est un ensemble de relations ( appelées tables ) qui vont regrouper toutes les informations du système d'informations.
Une table contient un ensemble d'informations qui ont un lien logique entre elles. On la représente souvent sous la forme d'un tableau à double entrée où les différentes valeurs d'un même attribut sont notées dans les colonnes et les différentes occurrences dans les lignes. On peut rapprocher cette notion de table de celle de fichier.
Ces tables sont composées d'attributs qui sont des données élémentaires d'une relation. Ce sont les colonnes de la table. En fichier, on parle de rubrique ou de champs.
Chacun de ces attributs prend ses différentes valeurs dans un domaine ( ensemble de valeurs possibles, par exemple un entier positif pour le numéro de machine, une date valide, un nombre de caractères pour le nom du responsable d'atelier ). Ceci correspond au type de la rubrique en fichier.
Dans chaque relation, on doit définir une clé ( attribut ou collection d'attributs ) qui sert à identifier de manière unique chaque occurrence de la relation. ( n° de machine pour la table machines ).
Attention : l'attribut n° atelier de la table MACHINES n'est pas une clé. Il servira à relier les deux tables.
On appelle tuple chaque occurrence d'une relation. ( une ligne ). La notion de tuple se rapproche de celle d'enregistrement ou d'article d'un fichier.
Un tuple ne peut se trouver qu'une seule fois dans une table.
L'ordre des lignes et des colonnes dans une table n'a aucune importance.
7.2.2. Représentation d'une relation.
On écrit le nom de la relation suivi entre parenthèses de tous ses attributs. On souligne la clé tout en la plaçant en tête des attributs. On peut souligner les clés étrangères avec des tirets. Exemple :
MACHINES (no-machine, type-machine,date-d-acquisition,cout-achat,no-atelier).
Parfois, on fait précéder les clés étrangères d'un # ou d'un *.
7.3. Les formes normales des relations.
Pour qu'un système d'informations implanté au moyen d'un S.G.B.D.R. soit optimisé, il est nécessaire que les relations la composant soient en troisième forme normale de Boyce-Codd.
On reconnaît 4 niveaux de forme normale :
- 1FN : première forme normale : si tous les attributs la composant sont en dépendance fonctionnelle de la clé de cette relation.
- 2FN : elle est en 1FN et si toutes les dépendances fonctionnelles liant la clé aux attributs sont des dépendances fonctionnelles élémentaires.
- 3FN : elle est 2 FN et toutes les dépendances fonctionnelles sont directes.
- 4FN de Boyce-Codd : elle est en 3 FN et il n'existe aucune dépendance fonctionnelle dont la source est un attribut non-clé de la relation et dont le but est un attribut composant cette clé.
7.4. La manipulation des données.
La S.G.B.D.R. doit présenter deux outils :
7.4.1. Le niveau de la création des données.
- Il est possible de créer les relations et donner la structure de la relation ( titres des colonnes ).
- Il est possible d'ajouter des tuples dans la relation, de les modifier et de les supprimer.
7.4.2. Le niveau de restitution des données.
Il s'agit de restituer à l'utilisateur toutes les informations demandées et uniquement celles-là. Pour réussir ceci, il faudra créer des relations ( tables ) virtuelles n'ayant qu'une existence momentanée et des outils appropriés.
7.4.2.1. Les opérateurs binaires.
7.4.2.1.1. L'opérateur UNION.
Il s'applique à deux relations ayant impérativement la même structure. Le résultat est une relation ayant la même structure et contenant les tuples issus des deux relations opérandes. Aucun tuple ne peut se trouver en double dans la relation résultante. Il faut donc contrôler les tuples au moment de l'opération.
7.4.2.1.2. L'opérateur INTERSECTION.
Il s'applique à deux relations ayant impérativement la même structure. Le résultat est une relation de même
structure et contenant les tuples présents dans chacune des deux relations opérandes.
7.4.2.1.3. L'opérateur DIFFERENCE.
Il s'applique à deux relations ayant impérativement la même structure. Le résultat est une relation de même
structure et contenant les tuples présents dans la première mais pas dans la deuxième ( l'ordre a ici de l'importance ).
7.4.2.1.4. L'opérateur JOINTURE.
Cet opérateur regroupe deux tables de structures différentes à partir d'une colonne qui leur est commune ( même si elle ne porte pas le même nom dans chacune des tables ). On collera alors les tuples des deux tables pourvu qu'ils aient la même valeur pour l'attribut commun. ( l'attribut commun ne formera qu'une colonne dans la table de jointure ). ( en portant un nom rappelant les deux noms initiaux ).
Si des tuples sont présents dans une table et pas dans l'autre, ils ne figureront pas da ns la table résultante. Un tuple d'une table peut correspondre à plusieurs tuples de l'autre table. Les regroupements figureront tous dans la relation résultante. Il ne faut pas avoir des noms de colonnes en double dans la relation résultante. On préfixera donc les noms communs par le début du nom de la table d'origine.
Rappelons également que l'ordre des colonnes n'a aucune importance.
7.4.2.1.5. L'opérateur PRODUIT.
Réalise le produit cartésien des deux relations opérandes. Il réalise le collage de tous les tuples d'une relation avec tous les tuples de l'autre relation.
7.4.2.1.6. L'opérateur DIVISION.
Se réalise sur des relations qui ont des structures similaires en ce sens que la structure de la relation diviseur doit âtre un sous-ensemble de la structure dividende. La relation résultat aura pour seuls attributs les attributs supplémentaires. C'est l'opération inverse de PRODUIT.
7.4.1.2. Les opérateurs unaires.
Nous allons maintenant travailler sur une seule relation.
7.4.1.2.1. L'opérateur SELECTION.
Il s'agit d'un opérateur essentiel. Il consiste à ne conserver que certains tuples d'une relation, ceux qui satisfont à une condition exprimée dans l'ordre de cette sélection.
Exemple : voici une relation :

COMTOUR = SELECTION (MACHINES, Type-Machine = 'Tour' ou Type-Machine = 'Comm.Numérique' et Date-Acquisition >= 01/01/1992) nous donne comme nouvelle table :
7.4.1.2.2. L'opérateur PROJECTION.
Il est aussi très souvent utilisé. Ici, on ne va conserver que quelques attributs d'une relation ( ceux dont la liste est donnée est donnée dans l'ordre de projection ).

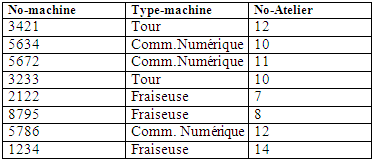
Subissant l'ordre : MACHINESIMPLIFIEE = SELECTION(MACHINES,No-machine,Type-machine, NO-Atelier) nous donne
Tandis que : MACHINESIMPLIFIEE2 = SELECTION(MACHINES,Type-machine) nous donne
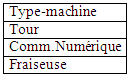
Pourquoi ?
7.4.1.2.3. L'opérateur CLASSEMENT.
Il permet de présenter les tuples d'une relation dans un ordre déterminé ( croissant ou décroissant) des valeurs de un ou plusieurs attributs de cette relation. La relation créée a la même structure que la relation de départ. On peut la comparer à un tri de fichier.
7.4.1.2.3. L'opérateur CLASSEMENT.
Il permet de présenter les tuples d'une relation dans un ordre déterminé ( croissant ou décroissant) des valeurs de un ou plusieurs attributs de cette relation. La relation créée a la même structure que la relation de départ. On peut la comparer à un tri de fichier.

Subissant l'ordre suivant : MACHINES1 = CLASSEMENT(MACHINES, No-Atelier ↓ ,Type-Machine ↑ ,No-Machine ↓) nous fournira la table suivante :

7.4.1.2.4. Les opérateurs de calcul et de comptage.
Ce sont des opérateurs qui vont permettre de réaliser des calculs ou des comptages de tuples dans une relation.
La table résultante est composée comme la précédente mais compte un nouvel attribut qui contiendra le résultat de l'opération. Ce nouvel attribut pourra servir dans d'autres opérations.

COMMVAL = CALCUL(COMMANDE, MontantHT = Quantité * PrixUHT)

On peut aussi effectuer la somme sur un seul attribut
TOTCOM = CALCUL(COMMVAL, totHT = SOMME MontantHT PAR NoCommande) nous donne

Il faut être prudent car le total d'une commande est écrit sur chaque tuple de cette commande. On aurait pu dire :
R1 = PROJECTION(TOTCOM, NoCommande, TotHT)
R1 = CALCUL(R1,Totgal = SOMME TotHT)
R3 = PROJECTION(R2,Totgal)

Le calcul à partir d'attributs de la relation et de constantes.
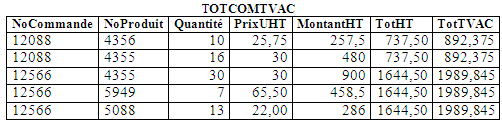
L'ordre TOTCOMTVAC = CALCUL(TOTCOM,TotTVAC = TotHT * 1.21) va créer la relation :
Détermination d'une valeur maximale ou minimale.
L'ordre MAXCOM = CALCUL(TOTCOM,MaxTotHT = MAX(TotHT)) va créer la relation :

On pourra ensuite déterminer le numéro de la plus grosse commande en complétant cet ordre des deux suivants :
MAXCOM1 = SELECTION(MAXCOM, TotHT = MaxTotHT)
MAXCOM2 = PROJECTION(MAXCOM1, NoCommande)
( vous réaliserez bien les relations résultantes ).
Il est bien entendu que le minimum peut être calculé de la même manière en remplaçant MAX par MIN.
Le comptage de tuples.
On peut éventuellement utiliser des regroupements de tuples grâce au complément de phrase PAR suivi du ou des attributs servant à faire ce regroupement. On réalise ainsi le COMPTAGE des tuples ayant la même valeur pour l'attribut ( ou la collection d'attributs ) spécifié (é).
Si aucun regroupement n'est spécifié, on compte le nombre de tuples de la relation.
Partons de TOTCOM et calculons le nombre de produits commandés et le montant moyen d'une commande.
REL1 = COMPTAGE(TOTCOM, Nbprod = NOMBRE DE TUPLES PAR NoCommande)
REL2 = PROJECTION(REL1, NoCommande, TotHT, Nbprod)
REL3 = CALCUL(REL2, Totcom = SOMME TotHT)
REL4 = COMPTAGE(REL3, Nbcom = NOMBRE DE TUPLES)
REL5 = CALCUL(REL4, Moycom = Totcom / Nbcom)
Vous aurez successivement les relations suivantes :




7.5. Comment écrire une suite d'ordres d'algèbre relationnelle ?
- Description de la relation résultat qui devra contenir toutes les informations attendues et uniquement celles-là.
- Recensement des informations nécessaires et localisation dans les relations de base ou celles déjà créées
- Représentation en tableaux de chaque relation obtenue à chaque étape
- Dégraissage des tables intermédiaires de tout attribut ou tuples inutile
----------------------------------------------------------------------------------------------
Précédent < Les Fichiers
Précédent < Les Fichiers
Article plus récent Article plus ancien








{kind=link}