


Cours Système D'analyse Merise : Principes et méthodes Merise
1. INTRODUCTION.
1.1. Définition de l’analyse.
1.1. Définition de l’analyse.
L’informatique est la science du traitement rationnel de l’information, notamment par machine automatique.
Les ordinateurs sont capables de traiter les informations très rapidement et en grande quantité. Toutefois, cette capacité de traitement, la vitesse à laquelle ils se feront et la fiabilité des résultats obtenus, ne peuvent être optimisés que si l’on passe au préalable par une préparation minutieuse des divers travaux à effectuer. Cette préparation se traduit bien en amont de l’élaboration des programmes par l’étude des informations que nécessitent ces traitements.
L’objet de l’analyse informatique est donc de mettre en évidence les informations nécessaires aux divers traitements permettant d’obtenir les résultats recherchés. On estime que cette analyse comporte 5 étapes :
- analyse préalable
- analyse conceptuelle ( ou analyse fonctionnelle )
- analyse organique
- programmation
- tests et mise au point
1.2. MERISE ?
MERISE est né en 1978 et s’est fortement implanté dans les entreprises. MERISE est caractérisé par :
Une approche systémique.
MERISE définit une vision de l’entreprise en terme de systèmes. On peut considérer qu’une entreprise est constituée de 3 systèmes :
- Le système de pilotage qui dirige l’entreprise et fixe les objectifs.
- Le système opérationnel qui assure la production.
- Le système d’information qui assure le lien entre les autres. Nous traiterons surtout celui-ci.

La séparation des données et des traitements.
Dans MERISE, les informations à traiter ( données ) et les traitements de ces données font l’objet de démarches d’étude séparées qui peuvent même être menées en parallèle par des équipes distinctes.
La conception par niveaux.
MERISE distingue 3 niveaux de description du système d’information :
- Le niveau conceptuel : son rôle consiste à définir précisément les qualités de l’entreprise. Il décrit l’ensemble des données stables ou variantes du système d’information et l’ensemble des règles de gestion à y appliquer sans tenir compte d’un quelconque matériel d’informatique devant supporter ces informations.
- Le niveau organisationnel ou logique : son rôle consiste à définir l’organisation qu’il est souhaitable de mettre en place pour atteindre les objectifs souhaités. On y précisera les postes de travail, la chronologie des opérations et l’emploi des bases de données.
- Le niveau physique ou opérationnel : il définit les organisations physiques des données et la description des traitements effectués par chaque unité de traitement.
Comme dans chaque niveau doit être respectée la séparation des données du traitement, cela peut se résumer :

En théorie, on peut procéder à une estimation du temps passé par étape :
Analyse de l’existant : 30 %
MCD + MCT + MOT : 40 % ( en parallèle )
MLD : 15 %
MPD et MopT : 15 %.
2. DEMARCHE D’INFORMATISATION.
L’automatisation des tâches d’une entreprise ne doit pas se faire d’une manière désordonnée mais découle d’une succession de phases.
2.1. Détection d’un besoin d’automatisation.
La détection d’un besoin d’automatisation provient généralement :
- d’un plan d’entreprise quand il existe
- de la demande émanant d’un service
- de l’observation de dysfonctionnements
Parfois, l’automatisation est existante mais ne rend pas tous les services attendus.
2.2. Etude d’opportunité.
L’étude d’opportunité ou de faisabilité va permettre d’étudier le projet d’automatisation et de décider de sa faisabilité technique, humaine ou financière. Cette étude peut être décomposée en étapes qui sont :
- Constitution d’un groupe d’étude : il doit être composé d’informaticiens mais aussi des organisateurs et des futurs utilisateurs. Un des responsables suivra le déroulement de l’automatisation jusqu’à sa mise en place.
- Etablissement d’un planning prévisionnel : il est établi par le groupe d’étude et portera sur les trois étapes suivantes.
- Analyse de l’existant : il s’agit d’identifier les flux d’informations et les stations traversées par ces flux en relevant les documents, les supports, les traitements et les avatars subis. Comment ?
+ Il faut procéder à l’interview de toutes les personnes concernées de près ou de loin par les informations. On pose les questions traditionnelles : qui, quoi, où, quand, comment, pourquoi, combien. On n’hésite pas à poser plusieurs fois les mêmes questions aux mêmes personnes car elles peuvent se contredire.
+ L’étude de tous les documents ( factures, formulaires, notes, informations verbales ) doit recouper les renseignements obtenus lors des interviews.
+ Tous ces renseignements seront résumés dans des schémas : Voici tout d’abord le
diagramme des flux :
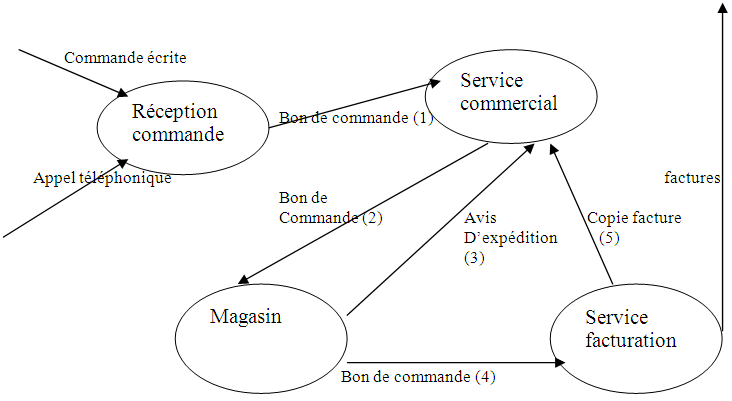
Schéma de circulation des documents

T1 : Création du bon ce commande (BC)
T2 : Enregistrement commande et visa du bon de commande
T3 : Préparation et envoi commande et création de l’avis d’expédition (AE)
T4 : Envoi du bon de commande pour établir la facture
T5 : Création de la facture (F) et de sa copie (CF)
- Critique de l’existant : fournit un état de la situation actuelle et tente de faire apparaître ( objectivement ) les défauts et les qualités de ce qui existe déjà. Cette critique peut déboucher sur la remise en cause des structures, des postes, des hommes, des documents…
- Ebauche de solutions : il s’agit d’établir une ou plusieurs propositions de solution globale, permettant de pallier aux carences repérées lors de la critique de l’existant. Il faut faire apparaître les axes fondamentaux des solutions proposées et les moyens à mettre en œuvre pour arriver à atteindre les objectifs fixés tout en respectant les contraintes détectées.
2.3. Le cahier des charges.
Le cahier des charges est un document mentionnant les délais, les coûts, les devoirs et les obligations de chacune des parties au contrat. Ce document engage donc le concepteur et le promoteur de l’automatisation.
2.4. Etude du système d’information.
Il s’agit de la partie conceptuelle de l’analyse. Nous allons développer tout particulièrement cette partie dans la suite du cours. Cette étude prendra en considération tous les éléments du système :
+ les entrées et les sorties d’informations
+ les traitements automatisables et les traitements manuels
+ les données
+ la structure des données
2.5. Etude du système informatique.
Il s’agit de la partie organique de l’analyse. Elle va définir l’architecture des éléments du système informatique à mettre en œuvre ( fichiers, bases de données, , entrées, sorties, traitements, …) en respectant les spécifications mises en évidence par l’étude du système d’informations et spécifiées par le cahier des charges.
2.6. Programmation et essais.
- conception des programmes (algorithmes, arbres programmatiques, …)
- écritures des programmes à l’aide d’un langage approprié
- mise au point des programmes à l’aide des jeux d’essais
2.7. Mise en place de l’application.
- en mettant directement l’application à disposition du client
- en remplacement des anciennes procédures
- en parallèle avec les anciennes procédures
3. L’INFORMATION.
3.1. Définition.
L’information est un élément qui permet de compléter notre connaissance sur un objet, un événement, un concept,…
Cette information peut se présenter sous diverses formes :
- la forme écrite
- la forme symbolique ( des signes particuliers,…)
- la forme orale
Le système d’information d’une entreprise peut alors être considéré comme étant constitué d’un ensemble de flux d’informations qui transitent entre diverses stations.

Les stations sont les endroits où l’information est traitée. Parfois, on peut subdiviser cette station en
sous-stations.
Le flux peut se traduire par des documents écrits ou par des informations orales échangés entre 2 stations.
Pour une automatisation réussie, l’information devra être cernée et classifiée de manière très précise et devra également pouvoir être représentable dans le système informatique. On distinguera ainsi :
- la classification de l’information
- le mode de représentation de l’information
3.2. Classification de l’information.
Les catégories d’informations.
- les informations élémentaires : on ne peut pas inventer sa valeur. Pour pouvoir s’en servir, on doit connaître sa valeur ( exemple : le nom d’un employé )
- les informations paramètres : un paramètre est une rubrique dont la valeur est constante et prévisible. On peut estimer que sa valeur est connue et la même pour tout et pour tous ( exemple : un taux de TVA connu et identique pour tous les articles )
- les informations résultantes : elles sont obtenues par un traitement arithmétique ou logique
- les informations de commande : il s’agit ici des traitements ( calcul, comparaisons ) à effectuer
Autres classifications des données.
- interne ou externe
- quantitative ou qualitative
- permanente ou temporaire
3.3. Le mode de représentation des données.
Il s’agit ici de déterminer de quel type les données seront utilisées par le programme
- alphabétique pur
- alphanumérique
- numérique
- date
- logique Booléen
Bien souvent, on détermine par la même occasion la taille de l’information.
3.4. Le dictionnaire des données.
Le recensement des informations est le préalable absolu à toute démarche d’automatisation. Il existe 2 méthodes :
- la méthode ascendante : très pratique pour une nouvelle informatisation ; elle consiste à étudier toutes les sorties à obtenir et à remonter vers les données nécessaires à l’obtention des résultats figurant sur ces sorties.
- La méthode descendante : à utiliser sur un système existant ; elle consiste à recenser toutes les informations du système rencontrées sur les divers documents en service et à y ajouter les nouvelles données nécessaires aux nouveaux traitements.
Le recensement des informations et de leurs catégories permet de constituer le Dictionnaire des Données ou parfois Lexique des Données. Il s’agit d’un tableau recensant l’ensemble des informations rencontrées lors de l’analyse préalable ou permettant de répondre aux objectifs du système d’information et mentionnant parfois la classification de l’information, son mode de représentation ainsi que sa longueur.
Afin d’identifier les données ( les rubriques du dictionnaire ), il conviendra d’affecter un nom à chacune. Il faudra éliminer les synonymes et les polysémes ( un mot qui désigne plusieurs choses différentes : comme une clé qui désigne un outil et qui sert à ouvrir une porte ).
On obtiendra ainsi un dictionnaire des données apuré des polysémes et des synonymes pour que tout le monde parle le même langage. On y inscrira également les contraintes d’intégrité ( par exemple les limites minimales et maximales d’une donnée ). On ne conservera que les rubriques élémentaires ( on supprimera les rubriques composées comme ADRESSE qui est composée de NUMERO, RUE, CODEPOSTAL, LOCALITE ). On obtiendra ainsi un Dictionnaires des données élémentaires. On y conserve également certains paramètres, des rubriques calculées de type situation ou historique.
Voici un exemple :
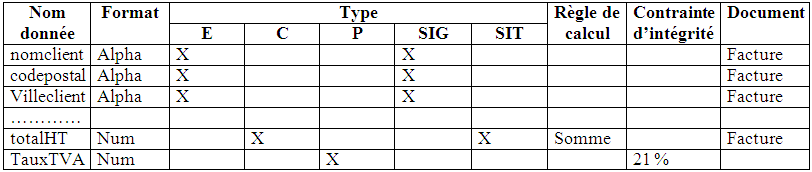
Les données ainsi recueillies vont alors permettre de réaliser un certain nombre de traitements :
- saisie de l’information ( clavier ,…)
- enregistrement sur un support ( disquette, CD DVD, bande, …)
- classement momentané ( fichier, base de données, …)
- classement définitif ( archivage )
- consultation ( écran,…)
- modification du contenu ( valorisation )
- diffusion ( impression, …)
- transmission à distance …
-----------------------------------------------------------------------------------------------
Article plus récent Article plus ancien







